
用 Claude Code 蒸馏一本书:三个段位,多数人卡在第一级

用 Claude Code 蒸馏一本书:三个段位,多数人卡在第一级
《Claude Code 蒸馏 33 本顶级育儿书》那篇发出来之后,有位读者在评论区问了我一句 —
能不能把你用 Claude 这个 Agent 提炼书籍的方法论,掰开讲一讲?
这个问题,值得专门写一篇。
上一篇我其实只端了菜,没给菜谱 — 你看着满桌好菜,却不知道是怎么做出来的,干着急。
所以今天这篇,专门写给他,也写给每一个想自己动手蒸馏一本书的人。从备料到火候,一步不藏。
先交代一下那篇文章背后是怎么干的。
我让 Claude Code 开了 7 个 agent 并行、烧了约 1000 万 tokens,把 33 本樊登推荐过的育儿书逐字逐句啃了一遍。最后熬出三样东西:一张 33 本书的全览图、一张告诉你”该听谁”的判断地图、一份十万字的 PDF。

数字看着唬人。但你先别被它吓到。
蒸馏 33 本和蒸馏 1 本,用的是同一套方法。把这套方法拆开,其实只有三个段位。你卡在哪一级,蒸出来的东西就差在哪一级。
我们一个一个说。
蒸馏一本书,其实有三个段位
先给你一把尺子,你好对号入座,看自己现在站在哪。
| 段位 | 你做的事 | 你拿到的东西 | 卡在哪 |
|---|---|---|---|
| 🥉 青铜 | 把书丢给它,“帮我总结一下” | 一段通顺的摘要 | 浅、随机、不能复用 |
| 🥈 白银 | 给它装一把”拆书刀”(skill) | 一份按固定方法论深挖的结构报告 | 一次一本,还差个成品 |
| 🥇 黄金 | 定好输出标准 + 一群分身并行 | 一整本可以反复看的成书 | 烧 token,但一劳永逸 |
大多数人,一辈子停在青铜。
不是 AI 不行,是他们没给 AI 一套”怎么拆”的标准 — 就像你请了个博士回家,却只让他帮你念报纸。
下面三段,我带你一级一级往上爬。
段位一 · 直接让它总结
这是最朴素的做法,你大概率已经在用了。
把一本书的电子版丢给 Claude,敲一句:“帮我总结这本书的核心观点。”
回车。几秒钟,一段通顺的摘要就出来了。
跟你在豆包里让它总结一条视频、一篇长文,是一回事。
这一步有用吗?有用。应付一次”这本书大概讲啥”的好奇,够了。
但你想拿它干正经事,三个天花板马上撞上来。
第一,深度只到”金句摘录”级。它会告诉你”这本书强调亲子关系的重要性” — 对,可这种话你不看书也写得出来。书里真正值钱的,是作者凭什么这么说、论证链在哪儿断、他自己没看见的盲点在哪。这些,一句”帮我总结”逼不出来。
第二,每次格式都不一样。今天三段话,明天五个点,后天心情好给你一张表。你要想蒸 33 本书横着比,根本对不齐。
第三,不可复用。这次的要求,下次得重新说一遍。蒸到第十本,你自己都嫌烦。
说到底,青铜段位的问题,不在 AI,在你 — 你没告诉它”该用什么方法拆”,它只能给你一个最大公约数的答案。
怎么办?
给它一把专门的刀。
段位二 · 给它装一把”拆书刀”
这一步,是整篇文章最关键的一跳。跨过去,你的 AI 就从”随口总结”变成”按一套方法论深挖”。
先说清楚,skill 到底是什么
很多人用 Claude Code 很久,都没真正用过 skill。
翻译成人话:skill 就是一套你预先写好的、教 AI 怎么干一件事的说明书。
你把”怎么拆一本书”这件事,一次性想清楚、写成固定的指令,存下来。以后每拆一本,AI 都照着这套说明书来,一刀一刀,刀法完全一致。
青铜段位是你每次口头吩咐,AI 临场发挥;白银段位是你把刀法刻进了刀里,谁来都是同一套动作。
这就是 skill 和”直接聊”的根本区别。
我用的这把刀:李继刚的「深度拆书机」
我没有自己从零写。我用的是 李继刚(GitHub 上叫 lijigang)开源的一把拆书 skill,名字叫「深度拆书机」(ljg-skill-xray-book)— xray,就是给一本书拍 X 光片,把骨头照清楚。
这把刀背后有个挺有意思的设计理念。
大意是说:你觉得一本书”没什么可学的”,往往不是书太浅,而是你投进去的脑力不够。同一本书,你投入的算力越多,能挖出来的结构就越多。读不懂不是书的错,是火候没到。
所以这把刀干的事,就是逼着 AI 别偷懒 — 用一套结构化的流程,把投入的”算力”拉满。
它怎么把一本书拆三层
具体怎么拆?三轮。一轮比一轮深。
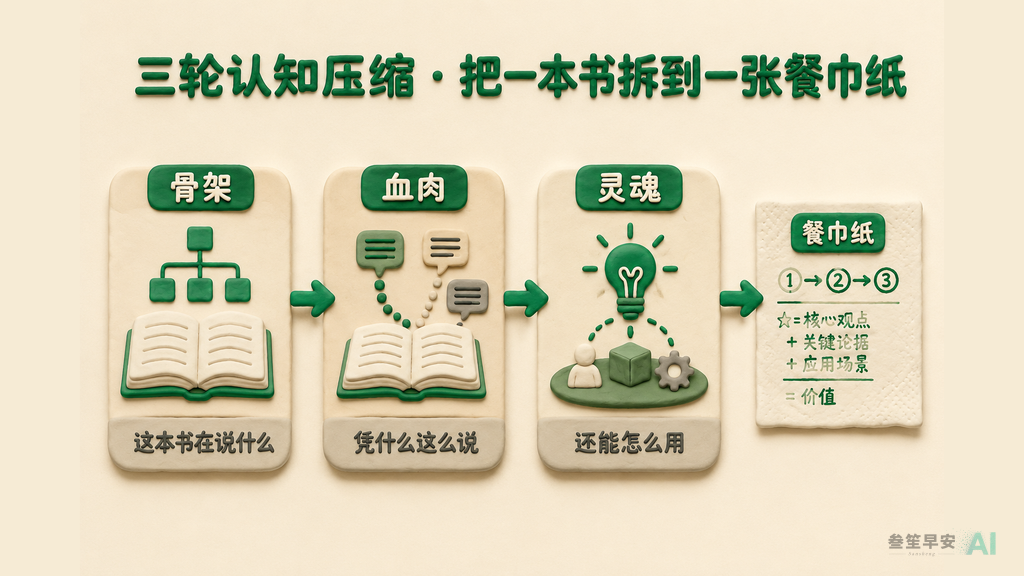
| 轮次 | 回答的问题 | 挖出来的东西 |
|---|---|---|
| 第一轮 · 骨架 | 这本书在说什么 | 核心问题、核心答案、章节结构、论证类型 |
| 第二轮 · 血肉 | 凭什么这么说 | 论证链、关键证据、隐形假设、什么情况下失效 |
| 第三轮 · 灵魂 | 还能怎么用 | 作者盲点、跨领域映射、和你已有知识的连接、读完该做什么 |
拆完三轮,它还会做一次”极限压缩”,逼出一张餐巾纸:如果这本书只能留一个公式、一句话、一张能在餐巾纸背面画完的草图,是什么?
光说你没感觉。我给你看真东西。
下面这张,是这把刀拆樊登《读懂孩子的心》拆出来的”餐巾纸公式” —

读懂孩子 = 父母(终身学习 × 无条件的爱)/ 控制焦虑
你品品这一个公式的信息量。
它把一整本书压成了一个除法:分子是父母的终身学习和无条件的爱,分母是控制焦虑。分母越大,商越小 — 几乎所有伤害孩子的行为,本质都是父母用”为他好”包装自己的焦虑。
这种东西,“帮我总结一下”是给不了你的。
手把手:把这把刀装上、用起来
讲到这儿,你肯定想问:这刀怎么拿到手、怎么用?
skill 的用法,简单到出乎意料。
一个 skill,本质就是一份写好的说明书。李继刚把它开源在了 GitHub(仓库就叫 ljg-skill-xray-book),README 里有一键安装的命令,照着装进 Claude Code 就行。
装好之后,调用更简单。在 Claude Code 里敲一句 — /ljg-xray-book 《读懂孩子的心》,剩下的交给它。
嫌找麻烦,照着上面那三轮(骨架、血肉、灵魂 + 餐巾纸)自己写一份说明书,也能用。重点从来不是某一把刀,是把刀法固定下来这件事本身。
到这一步,你已经能把任何一本书,蒸成一份有骨架、有论证、有盲点、还有一句话公式的深度报告了。
但我那篇文章,是 33 本。一本一本这么拆,得拆到猴年马月。
段位三 · 定好输出标准,再让一群分身一起干
从”拆 1 本”到”拆 33 本成一本书”,中间还隔着几道坎。
一是慢。一本一本来,33 本要拆到什么时候。
二是散。就算拆完了,你手里也是 33 份零散的文件,不是一本能拿出去的成品。
黄金段位,就是来迈过这几道坎的。具体,三件事。
第一件事:先定好成品长什么样
我对最后的东西是有要求的 — 它得是一份能直接发出去、能打印出来翻的 PDF,不是一堆 Markdown。
所以我先写了一个输出脚本,把”成品长什么样”定死:封面页、目录页、每个学派一张分隔页、每本书自动另起一页、页眉页脚加页码。
翻译成人话:我先画好一个模子,让 33 份报告全倒进去,出来就是一本书的样子。

这一步是黄金和白银的分水岭。白银段位你盯着”内容”;黄金段位你开始管”成品”。
第二件事:让一群分身同时开工
模子有了,该解决慢的问题了。
Claude Code 有个很多人没用起来的能力:它可以同时派出好几个 agent,各干各的,互不打架。
你可以把它想成包工头带队。你是工头,手里 33 本书的活,你不自己一本本啃 — 你招 7 个工人,一人分 4 到 5 本,同时开工。
我当时就开了 7 个 agent 并行,每个分一批书,各自按那把”拆书刀”的刀法拆。约 1000 万 tokens 烧下去,一个人要读几个月的量,一个晚上拆完。
第三件事:拆完再聚合,归出一张地图
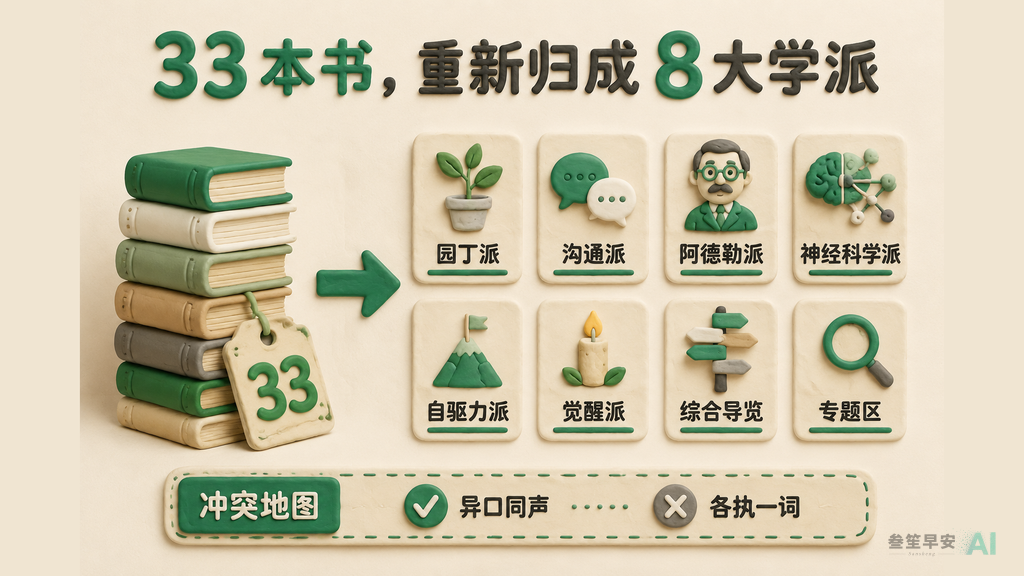
33 份报告都出来了,最后一步,是把它们拢成一张图。
我又写了个聚合脚本,把每本书的精华(那张餐巾纸、核心问题、灵魂洞察)抽出来,凑到一起,让 Claude 重新归类。
注意,是按理论根源归,不是按书名。
归完发现,33 本书其实分成 8 大学派 — 园丁派、沟通派、神经科学派、自驱力派、觉醒派…… 再叠一张”冲突地图”:哪些事这些专家异口同声(比如”吼叫有毒""控制欲是内驱力杀手”),哪些事他们各执一词(比如”到底该不该奖励孩子”)。
到这一步,你做的已经不是”读书笔记”了。
是造一本书。
| 黄金段位三件事 | 解决的问题 | 用到的能力 |
|---|---|---|
| 定输出标准 | 成品太散 | 一个渲染脚本(模子) |
| 分身并行 | 一本本太慢 | Claude Code 多 agent |
| 聚合再分类 | 一堆碎片没全局 | 抽精华 + 重新归类 |
这套方法,不止能蒸馏育儿书
我拿育儿书做例子,是因为上一篇是育儿。但你有没有发现 —
整套流程,跟”育儿”两个字一点关系都没有。
把书换掉就行。
换成一摞商业书,你能蒸出一张”管理思想地图”。换成一门专业课的全部教材,你能蒸出一份考前总纲。换成十几篇行业研报,你能蒸出一份”这个赛道到底在发生什么”。换成你想恶补的任何一个领域 — 同一套三段位,照跑。
至于你该用哪个段位,看你要什么。
临时了解个大概,青铜就够,别折腾。想要一份能反复翻的深度笔记,上白银,装把刀。要把一个领域系统啃透、还想要个成品,才上黄金。
杀鸡不必用牛刀,但你得知道牛刀在哪、长什么样。
说到底 — 蒸的不是书,是别人花几年读懂的东西。
顺便说个事:蒸馏一个人,靠谱吗?
说到蒸馏,这两年你大概率刷到过另一种更火的玩法 — 不蒸书,蒸人。
把一个人的语录、采访、文章全喂给 AI,让它学会这个人怎么说话、怎么思考,生成一个能跟你对话的”数字分身”。这股风最早是从”同事.skill”刮起来的,七万多人把自己同事蒸进了 AI。后来觉得蒸同事不过瘾,开始蒸名人 — 乔布斯、芒格、费曼,什么人都能蒸。
最有争议的一个,是张雪峰。
那位常年教人”务实填高考志愿”的网红老师,2026 年 3 月猝然离世,年仅 41 岁。人走了没多久,“张雪峰.skill”就上线了 — 项目方说,它基于他 5 本书、15 篇深度采访、30 多条一手语录,提炼出几个”核心心智模型”和完整的”表达 DNA”。
听着挺唬人。那它真能让你站在张雪峰的角度想问题吗?
我的判断是:别高估它。
我去翻了一圈实测和讨论,结论挺一致。有媒体把这些名人 skill 挨个试了一遍,给了个挺狠的定义 — 套着名人外壳的通用知识库。原话是:“只有乔布斯的味,但没有灵魂。”
为什么?因为你蒸的,根本不是那个人。
我打个比方。一个人真正值钱的判断力,长在他的私人经历里 — 那些没写进书、没在采访里讲过的踩坑、犹豫和临场决定。可你能喂给 AI 的,全是公开资料:传记、演讲、语录。蒸一个名人,蒸到的不是他本人,是他的**“公开形象”**。连张雪峰 skill 的开发者自己都承认,还原度大概只有五六成 — 真正的护城河,那些私底下的个人经验,蒸不出来。
这就是蒸人和蒸书最大的不同。
一本书,是作者花几年时间,把自己的思想系统地、完整地、亲手封装好的成品。你蒸它,蒸到的是作者本人交给你的完整论证。
一个活人,从没把自己系统化过。你蒸他,只能从外面的碎片里拼 — 拼出来的是个拟像。说白了:蒸书,蒸的是成品;蒸人,蒸的是拼凑。

当然,我也不把它一棍子打死。
“蒸馏一个人”有一种用法是成立的 — 不是拿它替代谁,更不是以为蒸完你就长了人家的脑子,而是把它当个”思维陪练”。你抛一个决定给”芒格”,看它会先问哪几个问题、会从哪儿挑刺。真正的收获不在它说了什么,在它逼你换一套框架,把自己的想法重新过一遍。
但也就到此为止。
它还踩着一条伦理的线。张雪峰的语录被第三方打包成 skill,家属从没点过头 — 人都走了,连”要不要被做成 AI”都没得选。科幻作家陈楸帆说得挺到位:一个 skill 一旦声称自己能代表一个人,它在哲学上就已经越界了。
所以回到那个问题:蒸书好,还是蒸人好?
想真正学到东西,我劝你蒸书。书里的核心观点,你能一条条提炼出来,消化成自己的判断。蒸一个人,热闹归热闹,你顶多得到一个陪你聊天的影子 — 别指望从它身上,偷来谁的脑子。
你可以照着做的全套清单
不啰嗦,给你一张能照着抄的清单。
| 第几步 | 干什么 | 备注 |
|---|---|---|
| 1 | 装好 Claude Code | 你已经会了,跳过 |
| 2 | 想清楚要哪个段位 | 决定后面投入多少 |
| 3 | 青铜:丢书 + 说要求 | 应急够用 |
| 4 | 白银:装一把拆书 skill,/ 调用 | 李继刚 ljg-skill-xray-book,或自己写三轮 |
| 5 | 黄金:定输出模子 + 开多 agent + 聚合 | 量大、要成品时才上 |
| 6 | 把书喂进去 | 原文喂入,别让它”凭印象” |
三个避坑提示,省得你踩我踩过的坑。
书要喂原文。 别指望它”凭记忆”复述一本书 — 它记得的是模糊印象,会编。把 txt、epub 或 PDF 原文喂进去,它拆的才是这本书,不是它脑补的那本。
黄金段位烧 token。 1000 万 tokens 不是小数目。如果你常干这事,一个能管够用的订阅档位,比按次买划算得多。
电子书走正规渠道。这个不用我多说。
好了,方法论交完了。
蒸馏一本书,就三步:青铜直接聊,白银装把刀,黄金定标准、上分身。
你真正要想清楚的,不是技术 — 是你到底想从这本书里,拿走什么。
想清楚了,剩下的,交给那把刀,和那群分身。
那位问我方法的读者,如果你看到这儿 —
菜谱,给你了。