
速递|DeepSeek V4 深夜开源:性能贴身,价格 1/7


速递|DeepSeek V4 深夜开源:性能贴身,价格 1/7
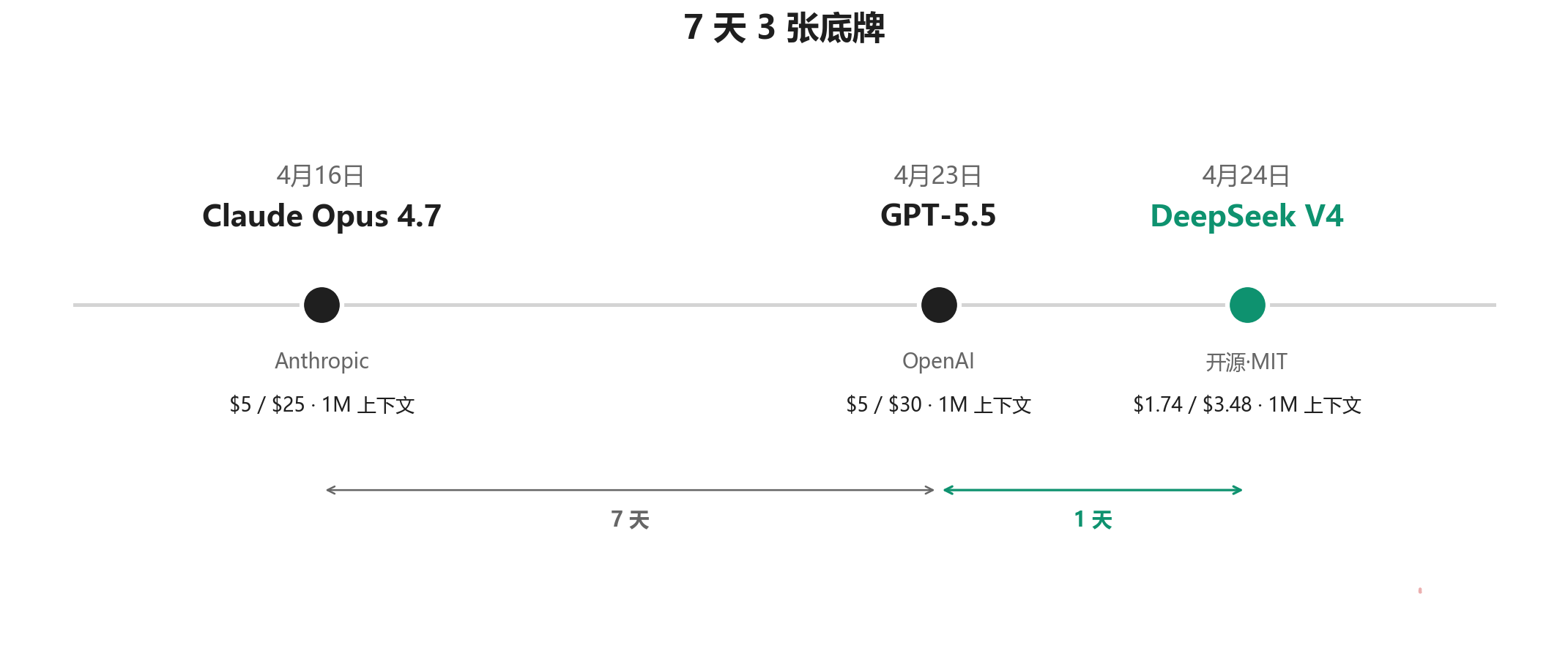
导读: 2026 年 4 月 24 日凌晨 3 点 24 分,DeepSeek 把 V4 预览版扔上了 HuggingFace。开源,MIT 协议,1.6T 总参数,1M 上下文,输出价 $3.48 每百万 token——正好是 Claude Opus 4.7 的 1/7、GPT-5.5 的 1/8.6。这是 7 天之内 AI 圈开的第三场发布会。这篇不讲情绪,只把三张牌摊到桌上。
这一周 AI 圈子,节奏有点乱。
4 月 16 日,Anthropic 扔出 Claude Opus 4.7;4 月 23 日,OpenAI 发布 GPT-5.5;4 月 24 日凌晨,DeepSeek 把 V4 直接开源放了出来。
7 天,三张底牌,全部亮完。
最后这张牌最特别。它不在闭源那一桌——它在开源这一桌,但对着闭源那一桌讲话。
60 秒速览
先把发生的事摆清楚。
时间: 2026-04-24 凌晨 3:24(北京时间),DeepSeek 官方 X 账号发出公告。
发布内容: DeepSeek-V4 预览版,一次性放了两个型号。
- V4-Pro:1.6T 总参数 / 49B 激活 / 1M 上下文 / MIT 协议
- V4-Flash:284B 总参数 / 13B 激活 / 1M 上下文 / MIT 协议
架构创新: 全新注意力机制 + 自研 DSA 稀疏注意力(DeepSeek Sparse Attention)。官方说法是,在 token 维度做了压缩,“实现了全球领先的长上下文能力,同时大幅降低计算资源和显存需求”。
API 同日上线: 接口同时兼容 OpenAI ChatCompletions 和 Anthropic 两套标准——这件事比听起来重要。改一行 model 参数就能切,原本挂在 Claude 上的 Claude Code、OpenCode、CodeBuddy 这些 agentic coding 工具,直接可以把 base URL 指到 DeepSeek。V4 带着整套 Claude 生态的兼容外壳出生。
三档推理: Non-think / Think High / Think Max。官方建议复杂 agent 场景用 Max。
权重已开放下载: HuggingFace 仓库 deepseek-ai/DeepSeek-V4-Pro,MIT 协议意味着可以商用、可以改、可以再发行。
性能贴身
发布会的核心当然是跑分。
先把重要的前提说了:DeepSeek 官方技术报告里用来对比的,是 Opus 4.6 和 GPT-5.4——不是 4.7 和 5.5。
原因不复杂。4.7 是 4 月 16 日发的,5.5 是 4 月 23 日晚上发的,V4 是 4 月 24 日凌晨发的。报告早就定稿了,来不及改对比基线。
所以下面这张表要这样读:V4-Pro 的对手,在发布当天已经被对方又往前推了一代。
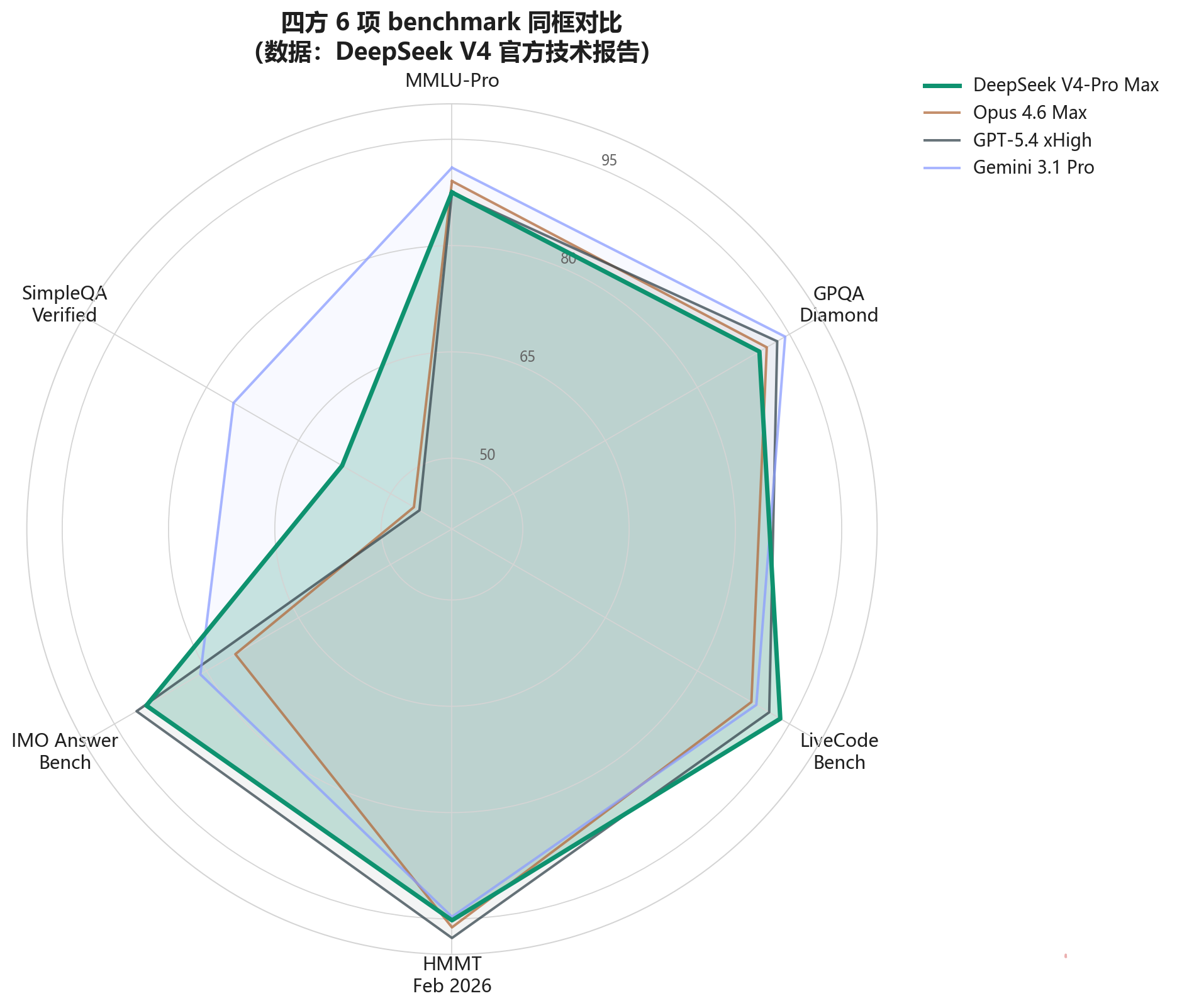
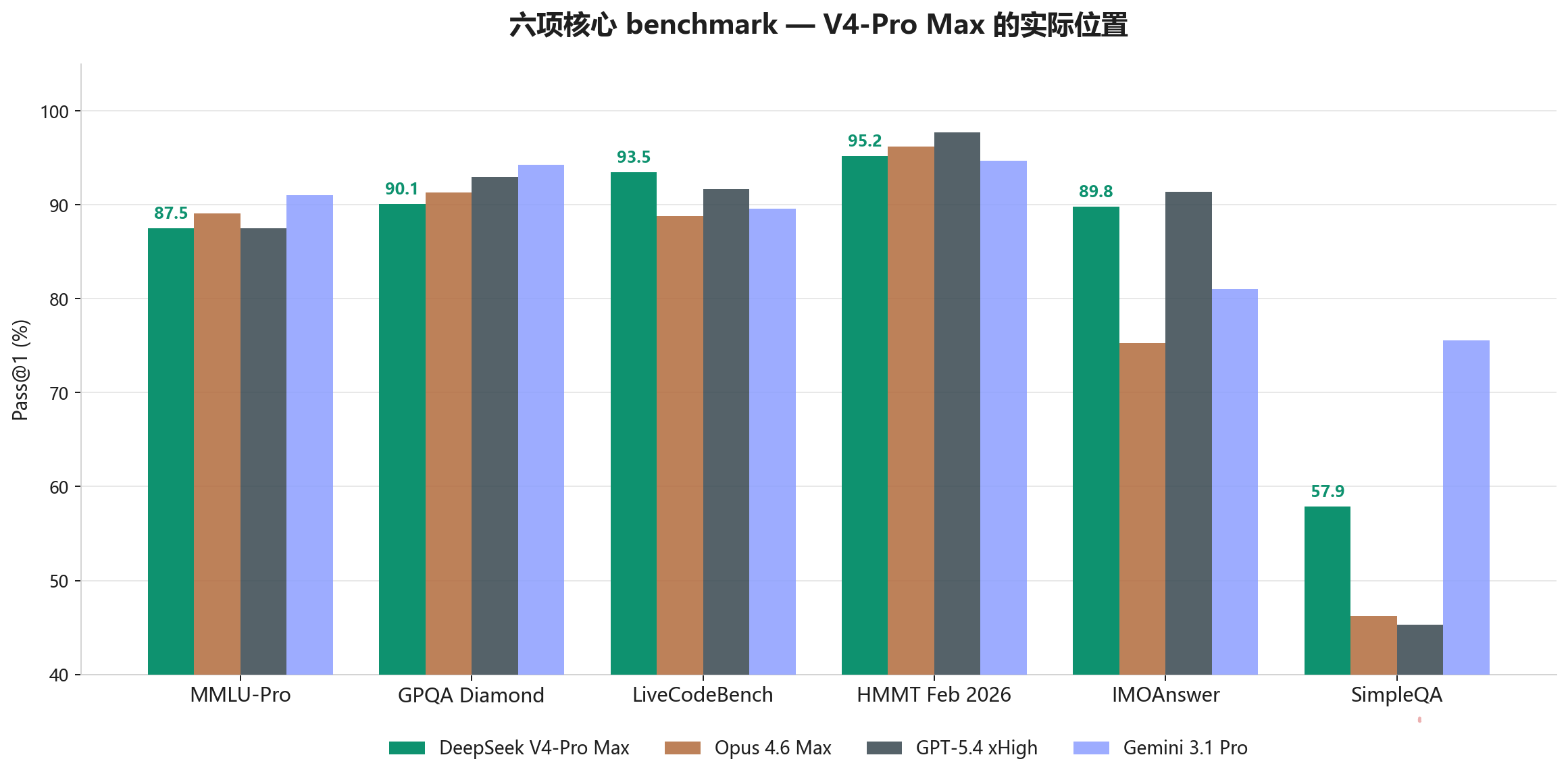
DeepSeek V4-Pro Max 档 vs 同代竞品(数据源:DeepSeek V4 技术报告)
| Benchmark | V4-Pro Max | Opus 4.6 Max | GPT-5.4 xHigh | Gemini 3.1 Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 89.1 | 87.5 | 91.0 |
| GPQA Diamond | 90.1 | 91.3 | 93.0 | 94.3 |
| LiveCodeBench | 93.5 | 88.8 | 91.7 | 89.6 |
| Codeforces (Rating) | 3206 | 3168 | 3052 | — |
| HMMT Feb 2026 | 95.2 | 96.2 | 97.7 | 94.7 |
| IMOAnswerBench | 89.8 | 75.3 | 91.4 | 81.0 |
| SimpleQA-Verified | 57.9 | 46.2 | 45.3 | 75.6 |
| Chinese-SimpleQA | 84.4 | 76.4 | 76.8 | 85.9 |
加粗是本项第一。
这张表的阅读方式很简单。六项里 V4-Pro 拿了 2 项第一(LiveCodeBench、Codeforces),其余 4 项贴身跟随。 知识与通用推理略逊 Gemini 3.1 Pro,硬核编程和竞赛代码反超闭源旗舰。
换成一张雷达图更直观——
DeepSeek 自己给的定位是”性能比肩顶级闭源模型”。更有意思的是 V4 发布稿里的一句话:V4-Pro 已经是 DeepSeek 公司内部员工使用的 agentic coding 模型,体感”优于 Sonnet 4.5,接近 Opus 4.6 非思考模式,但距 Opus 4.6 思考模式仍有差距”。
这是第一次有国产开源模型把自己的定位卡得这么精准——不吹”超越 Claude”,也不装”我们还差得远”。就说:我在 Sonnet 和 Opus 之间,偏 Opus 那边一点。
价格 1/7
真正的重头戏,在这里。
把这三张牌摆在同一张价目表上——
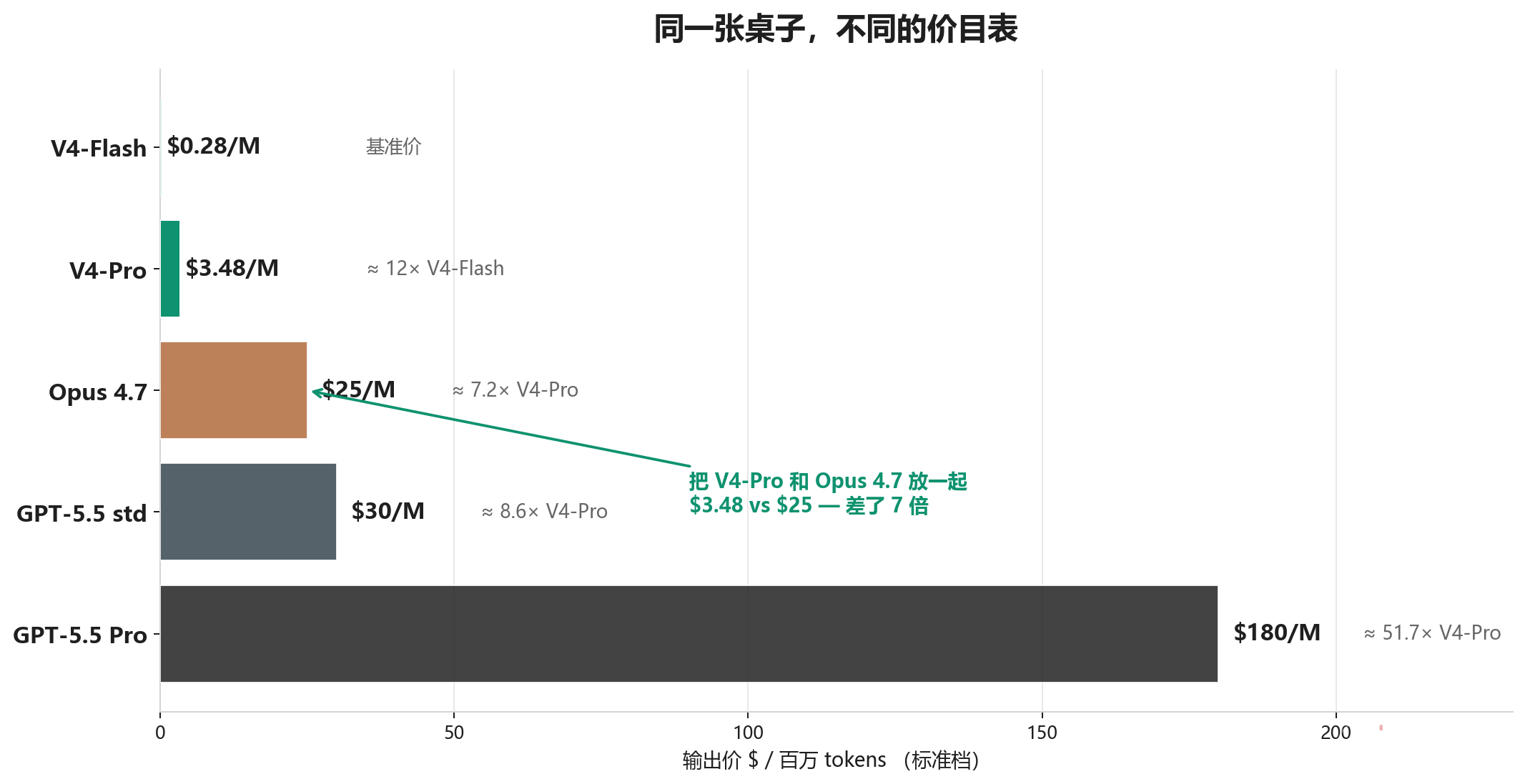
输出价对比($/百万 tokens,标准档)
| 模型 | 输入(cache miss) | 输出 | 备注 |
|---|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 | 轻量版 |
| DeepSeek V4-Pro | $1.74 | $3.48 | 旗舰 |
| Claude Opus 4.7 | $5.00 | $25.00 | 1M 上下文 |
| GPT-5.5(标准) | $5.00 | $30.00 | 1M 上下文 |
| GPT-5.5 Pro | $30.00 | $180.00 | 高精度档 |
把 V4-Pro 的 $3.48 和 Opus 4.7 的 $25 放一起——差 7.18 倍。
和 GPT-5.5 标准版比——差 8.62 倍。
和 GPT-5.5 Pro 比——差 51.72 倍。
这还没算 DeepSeek 那一套堆满的”再打折”机制:
- Cache hit 输入价:V4-Pro $0.145/M,只是 cache miss 的 1/12
- 夜间折扣:北京时间 23:00–07:00 所有请求 5 折
- V4-Flash:输出 $0.28/M,比 GPT-5.5 标准版便宜 107 倍
当然也要说 caveat。华尔街见闻引用 DeepSeek 官方的说法:V4-Pro 当前服务吞吐受限于高端算力,预计下半年华为昇腾 950 超节点批量上市后,Pro 版本价格将进一步下调。
也就是说,$3.48 还不是终点。
翻译一下:国产开源旗舰的价格,往后还要往下走。
一周三场
所以这一周到底发生了什么?
我只留两个观察。
1. 发布节奏按”周”算了
去年这时候,旗舰模型之间的更新窗口还是”季度”——你发一个,我等三个月再回。
今年这个月,我们看到的节奏是:
- 4 月 16 日 → Opus 4.7
- 4 月 23 日 → GPT-5.5
- 4 月 24 日 → DeepSeek V4
7 天 3 场,连气都不让对手喘。
这意味着一件事:对任何一个做 AI 应用的团队来说,“锁定一个模型做三个月”的日子已经结束了。下一个做决定的时间点,可能就是下周。
2. 开源这条线上,价格被按下去了
过去一年,闭源阵营涨价是主旋律——GPT-5.5 相对 GPT-5.4 直接把输入输出都翻了 2 倍($2.5/$15 → $5/$30),Opus 4.7 保持 Opus 4.6 的 $5/$25。
开源这边呢?
- 3 月 9 日 V4-Lite 出来的时候,DeepSeek 把价格往下打了一次
- 4 月 20 日 Kimi K2.6 出来,把开源编码价格基线又往下拉
- 4 月 24 日 V4-Pro 出来,$3.48 直接把旗舰档的开源天花板压到 1/7
闭源在涨、开源在降。 这条线没画错的话,对做 Agent、做高吞吐 API 调用、做企业级 RAG 的团队来说,2026 年 Q2 的成本账得重新算一遍。
这张牌今天已经摊完了。
权重可以下,API 可以调,价目表可以算。剩下的事,看你怎么用。


DeepSeek 官方:HuggingFace 技术报告
deepseek-ai/DeepSeek-V4-Pro、X 账号 @deepseek_ai 发布公告(2026-04-24 03:24 CST)友商定价:Anthropic 官方 Opus 4.7 pricing、OpenAI GPT-5.5 发布页(2026-04-23)
中文第一方:华尔街见闻《DeepSeek V4 预览版发布》(2026-04-24)、界面新闻、东方财富
评测参考:SCMP、France 24、handyai.substack《Model Drop: DeepSeek V4》、Artificial Analysis
数据截至:2026-04-24 12:00 CST