
Kimi 2.6 放下笔,拿起键盘:国产开源第一次贴着 Opus 打


Kimi 2.6 放下笔,拿起键盘:国产开源第一次贴着 Opus 打
导读: 2026 年 4 月 21 日凌晨,月之暗面悄悄开源了 Kimi K2.6。整个发布页面里,“写作”两个字一次都没出现。那个曾经靠 200 万字长文档出圈的 Kimi,在这一版里主动砍掉了自己最拿手的那条腿——换来的,是在 SWE-Bench Pro 上压过 Claude Opus 4.6 的 5.2 分。
2026 年 4 月 21 日凌晨,北京的天还没亮。
月之暗面在 Hugging Face 上丢出了一个模型:Kimi K2.6。没有发布会,没有预热视频,甚至连一张炫酷海报都没有。只有一条 Twitter,和一张密密麻麻的 benchmark 对比表。
表的左边一列是 Kimi K2.6,右边三列依次是 GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro。
这是国产开源模型,第一次把自己的名字,端端正正地摆在这三家海外顶级闭源模型旁边。
但更反常的是另一件事。
翻遍整个发布页面,“写作""创作""中文”——这些过去三年让 Kimi 出圈的关键词,一个都没出现。
那个最会写的 AI,这次决定不写了。
一个会写的 AI,为什么决定不写了
要回答这个问题,得先回到 Kimi 过去三年的那张”脸”。
2023 年 10 月,Kimi Chat 上线的第一天,月之暗面打的是一张很清晰的牌:长上下文。那时候 GPT-4 的上下文是 32K token,Claude 是 100K,Kimi 直接给到 20 万字,后来一路拉到 200 万字。
在中文互联网的一段时间里,“Kimi 能读 PDF”变成了一种集体记忆。律师用它读合同,学生用它读论文,产品经理用它读需求文档。 Kimi 的卖点在大众心里简化成了三个字:读、长、准。
到了 2025 年,Kimi 的能力标签进一步扩张——视觉驱动编程、智能体集群、高级办公指令处理。2026 年 1 月发布的 K2.5 还在强调”深度集成 Word、Excel、PPT”,让用户”一句话生成完整演示文稿”。那时候 Kimi 在向”会写、会读、会做办公”的综合助手上走。
然后就到了 2026 年 4 月 21 日的这个凌晨。
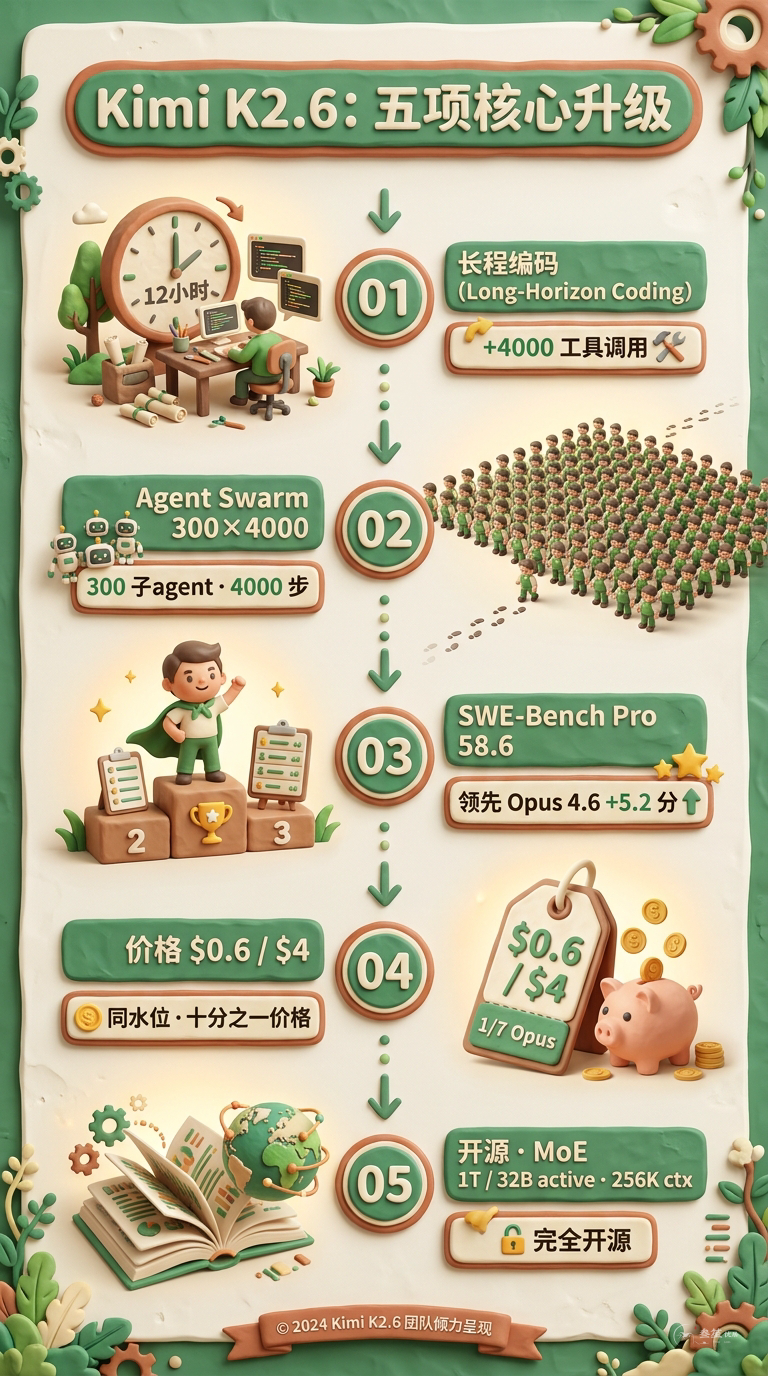
Moonshot 官方的 K2.6 发布材料里,核心关键词只有四组:
- Long-Horizon Coding(长程编码)
- Agent Swarm(智能体集群,300 子 agent × 4000 步)
- Coding-Driven Design(编程驱动的设计)
- Tool Use(工具调用)
四组关键词全都围着一件事转:让 AI 独立完成几个小时、几千步的真实工程任务。
而”写作”、“创作”、“长文档”、“办公自动化”——K2.5 时代的半边江山——在 K2.6 的发布材料里一字未提。
| 版本 | K2.5(2026-01) | K2.6(2026-04) |
|---|---|---|
| 长文档阅读 | ✓ 核心卖点 | ✗ 不提 |
| 写作 / 中文创作 | ✓ 隐性标签 | ✗ 不提 |
| 办公三件套 | ✓ 重点强调 | ✗ 不提 |
| 视觉驱动编程 | ✓ 新增 | ✓ 升级为 Coding-Driven Design |
| 智能体集群 | ✓ 最多 100 agent | ✓ 扩大到 300 agent × 4000 步 |
| 长程编码 | — | ✓ 核心卖点(12 小时 + 4000 工具调用) |
这是一次明显的”减法”。
一家公司,在它的产品发布页上,主动删掉自己过去三年积累的最强认知——这在国内 AI 圈,并不多见。大多数厂商选择的是”加法”:功能加加加,场景堆堆堆,生怕漏掉任何一个用户群。
Kimi 反着来了。
划重点
- Kimi K2.6 的官方关键词里,只剩编程、Agent、工具调用——和 K2.5 相比,写作/办公/长文档完全消失
- 这不是 Kimi 的又一次迭代,是一次主动的”人设减法”
- 一家公司敢砍掉自己最拿手的一边,往往意味着它在更深的地方想清楚了什么
贴着 Opus 打,但打的不是 4.7
Kimi 敢这么减,是因为它手里有牌。
我们先看月之暗面官方公布的 benchmark。这里先做一个必须讲清的声明——
月之暗面选的对标对象,是 Claude Opus 4.6,不是刚刚发布的 4.7。
Anthropic 在 4 月中旬刚刚推出 Opus 4.7,完整 benchmark 还没有公开披露;月之暗面的测试和对比数据,锁定在 4.7 出现之前。所以接下来的分项对比,主要是 K2.6 vs Opus 4.6——这个前提不讲清,后面所有数字都会让懂行的读者皱眉。
好,声明说完,看数据。
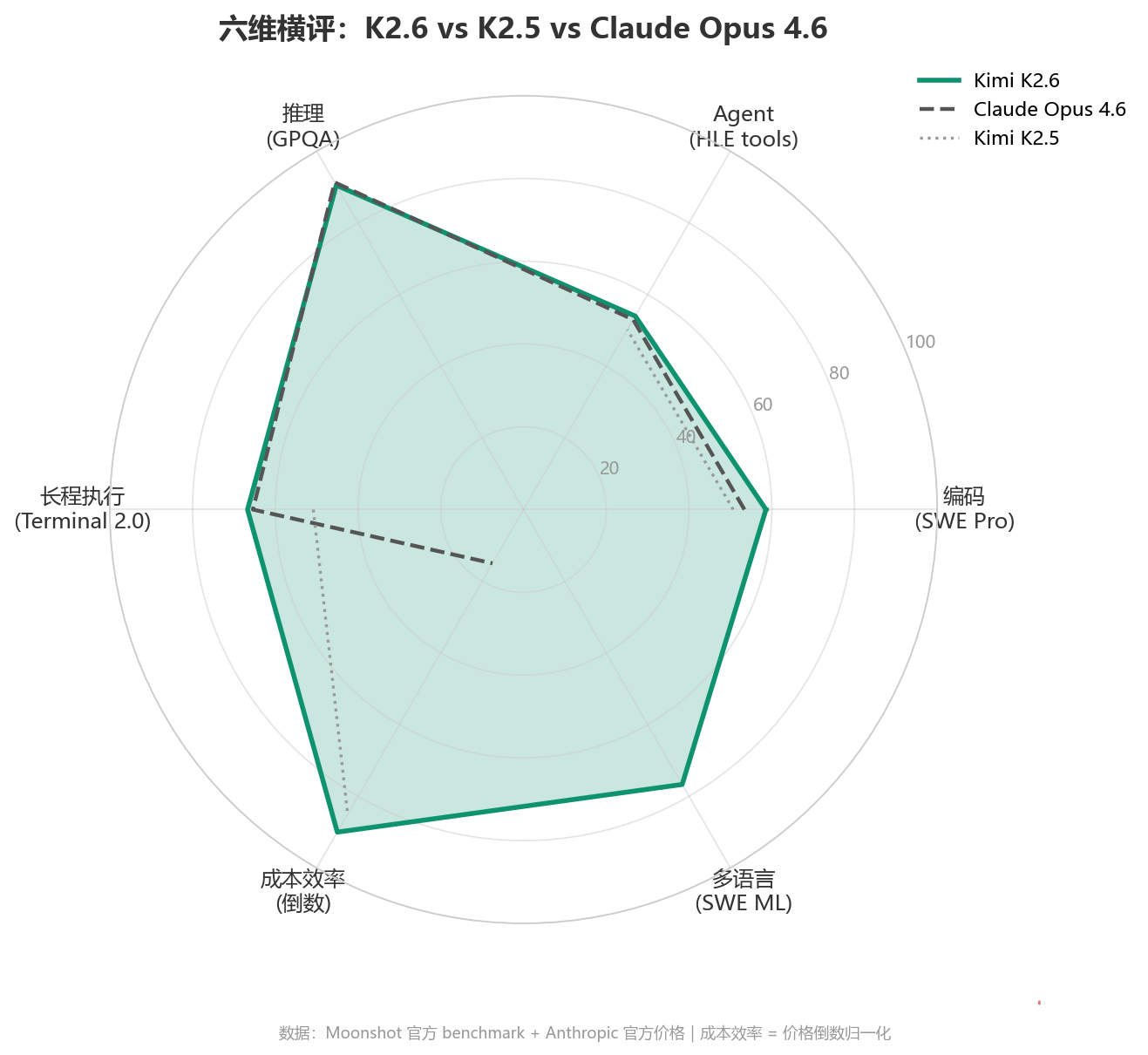
雷达图是全文六维横评的总览:编码与长程执行,K2.6 已经把 K2.5 甩开;推理维度 K2.6 与 Opus 4.6 接近,略微落后最顶尖的 GPT/Gemini;成本效率一档,断崖式领先。
编码:K2.6 在”最难那一档”上压过了 Opus
SWE-Bench Pro 是目前最贴近真实工程的编码基准——它测的不是单文件改 bug,是多文件、多步、涉及完整 repo 的 bug 修复,接近一个初级工程师的典型任务。
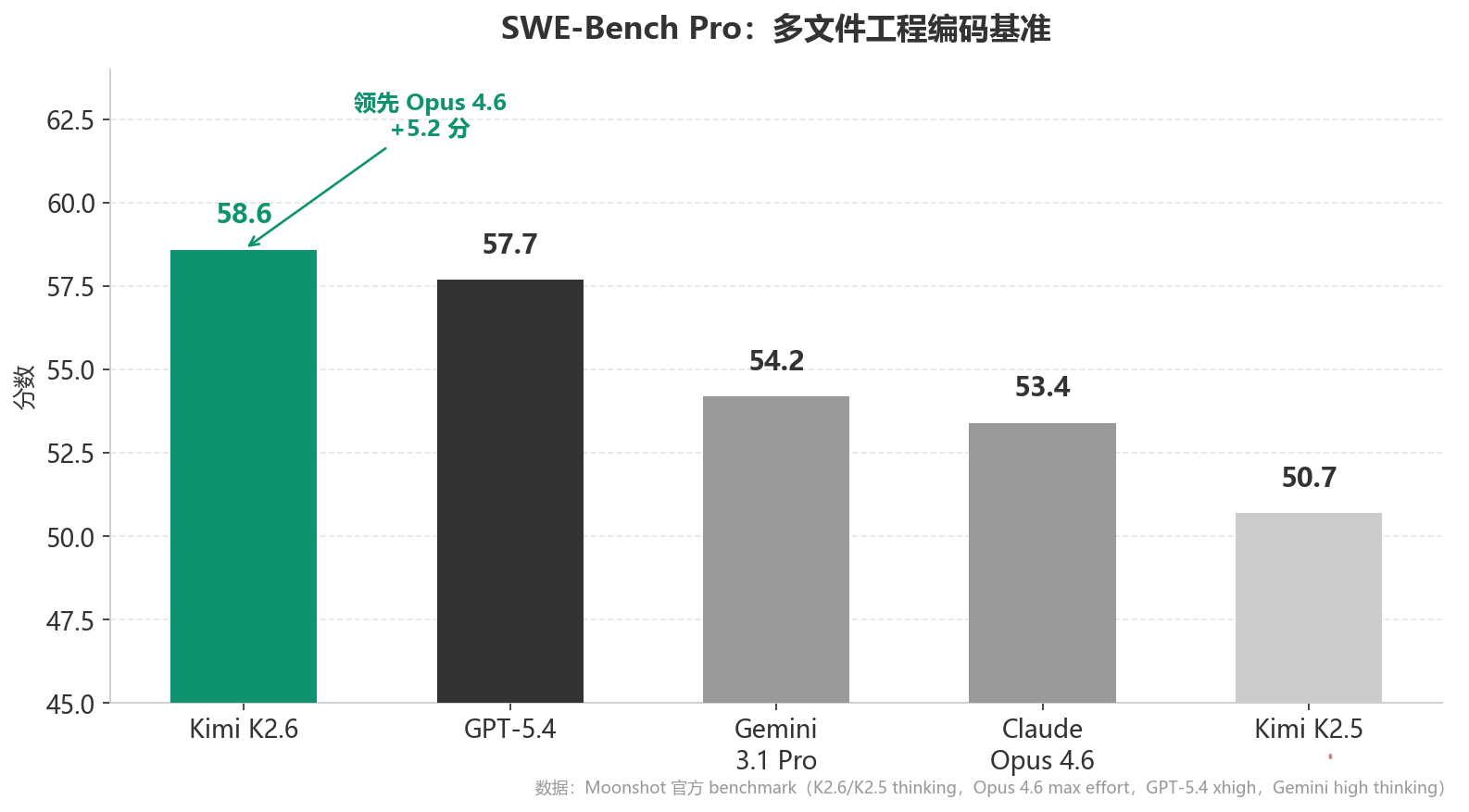
K2.6 领先 Opus 4.6 整整 5.2 分,领先 GPT-5.4 0.9 分。
这不是误差带内的持平,是真实的领先。而且 K2.6 比自己的上一代 K2.5 提升了 7.9 分——一个模型在 3 个月里能把最难的编码基准推高近 8 分,这个加速度本身就说明公司把资源押到了哪。
但另一头,SWE-Bench Verified(单文件 bug 修复)上,四家模型挤在一个 0.6 分的带子里:Opus 4.6 80.8、Gemini 80.6、K2.6 80.2——基本上是平手。
一句话解读:越复杂的工程场景,K2.6 的优势越大;越简单的编码任务,大家打平。 这个差异,和月之暗面”长程编码”的叙事完全对得上。
Agent:K2.6 的主场
Agent 维度是 K2.6 表现最锋利的一面。
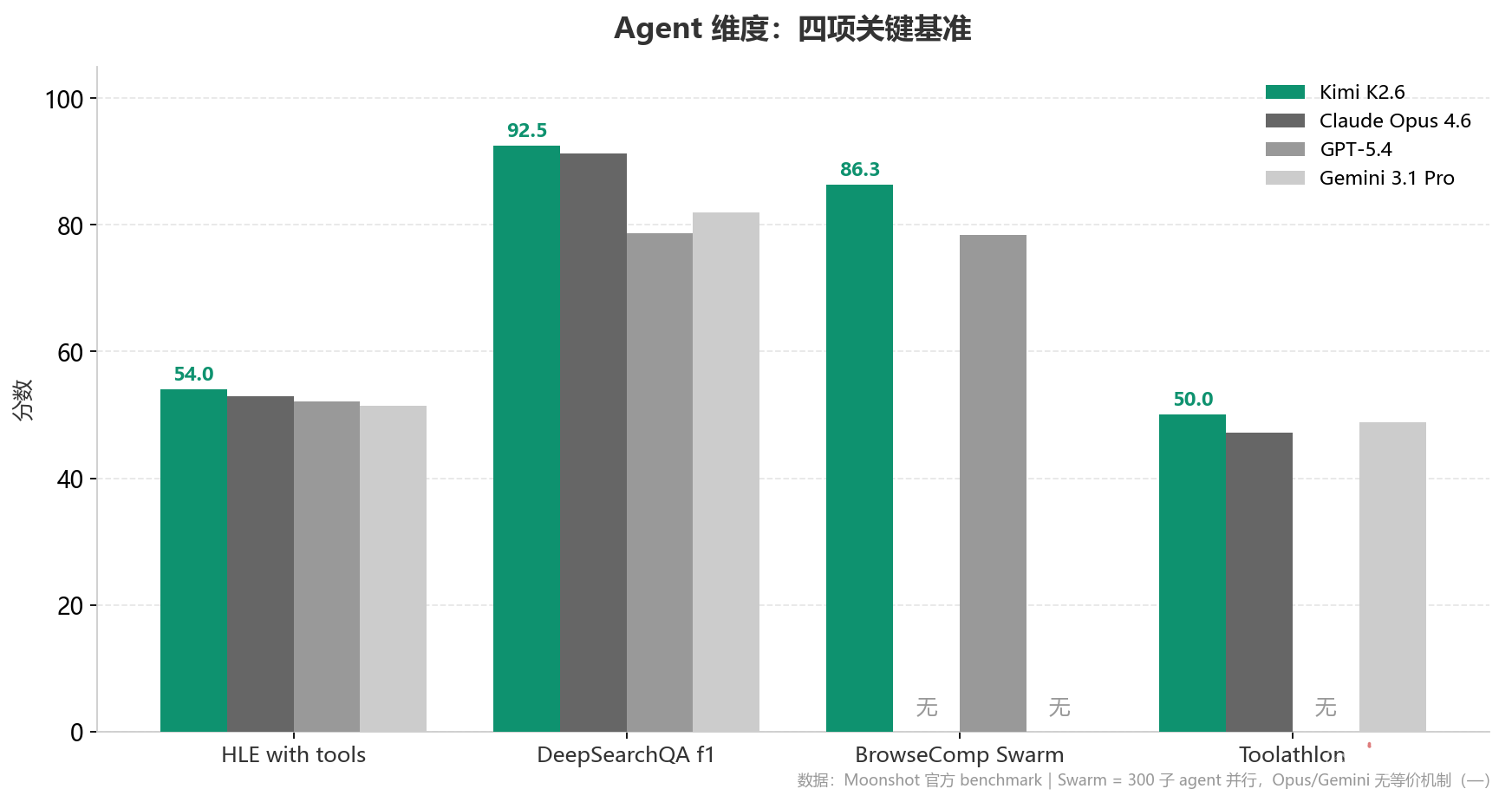
HLE、DeepSearch、Toolathlon 这三项,K2.6 全部小胜。
最锋利的一刀落在 BrowseComp Swarm 上。
K2.6 86.3,GPT-5.4 78.4,差 7.9 分。Opus 4.6 和 Gemini 3.1 Pro 这一格直接空缺——不是因为分数低,是因为它们没有原生的 Swarm 能力。K2.6 可以一次调度最多 300 个子 agent 并行,每个走 4000 步;Claude 和 Gemini 目前没有等价的机制。
这不是分数差异,这是结构性差异。
推理:K2.6 还是追赶者
但 K2.6 并不是全线碾压。
| 基准 | K2.6 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| AIME 2026 | 96.4 | 96.7 | 99.2 | 98.3 |
| GPQA-Diamond | 90.5 | 91.3 | 92.8 | 94.3 |
纯推理——数学竞赛、研究生级科学题——K2.6 仍然是追赶位。AIME 比 GPT-5.4 少 2.8 分,GPQA 比 Gemini 少 3.8 分。差距不大,但没摸到头部。
这个诚实必须讲。
写作呢?官方没数据,用户有说法
发布材料里没有 WritingBench、中文写作对比、公文写作这类基准。
但掘金和 Reddit 的实测帖里,用户的反馈相当一致——“思维链有 Opus 的风格”、“开源模型里最接近 Sonnet 的水平”、“指令遵循稳,输出结构不崩”。
推理一下:Kimi 的写作能力大概率没退,但 Moonshot 已经不再把它当卖点。写作变成了副产品,不是产品本身。
关于 Opus 4.7 的那段”错位补充”
最后回到开头那个声明——Opus 4.7 的完整 benchmark 还没公开。
Anthropic 官方的说法是:新旗舰、同价($5 / $25)、仅支持 adaptive thinking、新 tokenizer 可能让同请求略贵。 第三方测试还在陆续披露中。
我的预判是:即便 4.7 比 4.6 多涨 2-3 分,K2.6 在 SWE-Bench Pro 和 Swarm 上的领先仍然成立;但推理维度 4.7 很可能会进一步拉开差距。
这是国产开源模型第一次,贴着 Claude 打。不是碾压,不是反超,就是贴着——在对方熟悉的赛道上,用自己的定义,站到同一条起跑线上。
划重点
- 所有 benchmark 都有测试条件限制:K2.6/K2.5 开 thinking、Opus max effort、GPT-5.4 xhigh、Gemini high thinking——跨厂商的”max”不是同一个东西
- K2.6 在 SWE-Bench Pro(+5.2 vs Opus 4.6)和 BrowseComp Swarm(+7.9 vs GPT-5.4)上优势明显
- 纯推理 K2.6 仍是追赶者,AIME 差 GPT-5.4 2.8 分
- 月之暗面的对比对象是 Opus 4.6,不是 4.7——这个错位必须知道
十二小时的工程代理
光看分数,其实不够。
真正让我重新理解 Kimi K2.6 的,是月之暗面在发布页里放的两个案例。
案例 A:一段 Zig 代码,12 小时
任务:优化 Qwen3.5-0.8B 在 Mac M3 Max 上用 Zig 写的推理代码。
K2.6 接到这个任务之后,开始独立工作。
连续运行 12 小时以上,发起超过 4000 次工具调用,最后跑出来的推理速度,超过了 LM Studio。
4000 次工具调用意味着什么?意味着平均每 10 秒 K2.6 就要做一次”下一步怎么办”的判断——该读哪段代码、该跑什么 profile、该改哪个函数、该用什么编译选项。每一次都不能偏航,每一次错误都要能自己回滚。
这个过程里,没有人坐在旁边给它提示。
案例 B:一个 8 年老代码,改线程拓扑
第二个案例更有意思。
K2.6 被交给了一份叫 exchange-core 的代码。这是一个 8 年历史的开源金融撮合引擎,用于高频交易场景。Moonshot 让 K2.6 独立去优化它。
13 小时后,K2.6 交出的是这样一份成绩单:
- 完成 12 轮不同方向的优化 pass
- 发起超过 1000 次工具调用
- 修改了 4000+ 行代码
- 中位吞吐量从 0.43 MT/s 提到 1.24 MT/s,+185%
- 峰值吞吐量从 1.23 MT/s 提到 2.86 MT/s,+133%
最关键的动作在中间某一轮——K2.6 读了 CPU flame graph 和 allocation flame graph,判断出线程拓扑配置有问题,自己把原来的 4ME+2RE(4 个匹配引擎 + 2 个风险引擎)线程结构,改成了 2ME+1RE。
这不是在”写代码”。这是在做架构决策。
为什么这两个案例重要
在过去的语言模型叙事里,“写代码”和”写文章”是对称的——都是在生成 token。
但 K2.6 的这两个案例里,“写”这个动作可能只占 5% 不到。剩下 95% 是什么?
是读代码、跑基准、分析 flame graph、判断瓶颈、决定下一步、发起工具调用、检查结果、回滚错误、再试一次。
Kimi 不再是一个语言模型,它选择成为一个工程代理。
这个判断说出来简单,落下来是月之暗面过去一年多的整个战略重心。
那条更难走的路
K2.6 这次转身,不是一次工程师情绪发作,是一家公司在一年之前就开始想清楚的事。
把时间拨回到 2025 年春节。
那一年的农历新年前后,DeepSeek 突然火遍全网。一家原来搞量化的公司,用一个不到 600 人的团队,把模型效率推到让硅谷抬头看的水平。
月之暗面那个时候在干什么?那一年,它花在营销投放上的钱——接近 9 亿元人民币。街头地铁站的 Kimi 广告,朋友圈里的 Kimi 刷屏,大 V 带货式的 Kimi 推荐——都是这 9 亿换来的。
DeepSeek 这一下,让月之暗面内部经历了一次”深刻乃至痛苦的反思”(这是来自公司内部信的原话)。
反思之后的动作,非常决绝:
- 2025 年初,停掉全部市场营销和买量投放
- 解散买量团队
- 把所有资源,压到基座模型和 Agent 能力上
月之暗面总裁张予彤后来讲过一句话,我觉得是今天理解 K2.6 最好的注脚:
“与资源更多的大公司竞争时,我们会刻意控制业务边界——不做生活娱乐、不做多模态生成业务。专注大模型层、逻辑层、Agent 层,以及深入研究、PPT、数据分析、网站开发这类偏生产力、偏复杂任务的链路。”
从 2025 年初这一刻起,Kimi 就已经决定了不再”讨好所有人”。
生活娱乐不做,多模态生成不做,新闻播报不做,短视频脚本不做——这些在中文 AI 市场里本来都是高 DAU 高话题的方向,Kimi 一个没碰。剩下的,只有那条最窄、最难、最慢的路——偏生产力、偏复杂任务。
K2.6 的长程编码和 300-agent Swarm,就是这条路走到 2026 年 4 月的那个答案。
一家公司在 2026 年的春天,主动在产品页上砍掉”写作”——这件事放在 2024 年的月之暗面身上,是不可想象的。那时候的 Kimi,恨不得让每个用户都觉得”这就是你要的 AI 助手”。
一家公司最大的勇气,从来不是把功能加到极致,而是把自己的人设主动砍掉一半。
划重点
- Kimi 2.6 的”放下笔”不是一次意外,是月之暗面在 2025 年春节 DeepSeek 出圈后做出的战略选择
- 停掉 9 亿营销,解散买量团队,把资源全部压到基座模型和 Agent 能力
- 张予彤原话:不做生活娱乐、不做多模态生成,只做偏生产力、偏复杂任务的链路
- K2.6 是这条路走到 2026 年春天的一个阶段性答卷
这场变局,还没结束
写到这里,我想讲三件 K2.6 没那么美好的事。
第一,推理速度慢。 掘金上有个实测用户讲,K2.6 的首 token 延迟比 GLM 5.1 慢一个量级。MoE 1T 参数 + 激活 32B,调度开销本身就大;再加上 K2.6 刚发布,推理优化还没到位。跑重度 Agent 任务时,等待时间会明显感觉到。
第二,Kimi Code 的会员额度是按周刷新,不是按月。 重度 Agent 开发者一天就能把一周的额度用掉四分之一。这不是坑,是 Kimi 定的机制——但第一次订的人容易踩。
第三,纯推理 K2.6 还是追赶者。 AIME、GPQA 上被 GPT-5.4 和 Gemini 拉开 2-4 分。数学竞赛和研究生级科学题,Kimi 没摸到头部。
我之所以要把这三件事讲出来,是因为K2.6 现在不是”已经超过了 Opus”——它是”在自己选择的那条赛道上,第一次可以抬头和 Opus 对视”。这个区别很重要。
但即便这样,这次发布对国产模型的意义,还是不能小看。
回头看 2026 年 Q1 到 Q2 这几个月,国产开源组发的模型名字排在一起——DeepSeek V4、GLM 5.1、MiniMax M2.7、Kimi K2.6——每一家都在自己选的维度上,贴住了闭源顶尖。
这不是哪一家单独的胜利,是一个赛道集体到了分化临界点。
- Kimi 走向 Agent + 长程编码
- DeepSeek 守住基础研究 + 极致性价比
- MiniMax 押注多模态 + 全球化
- 智谱 GLM 在商业化 + 工具链上加码
- 字节豆包吃中文日常场景
- 阿里通义往企业级长文本走
没人再幻想”通用大模型一把抓”。 每一家都在学会说”我不做什么”。

在更远的一层,Anthropic 的 $5/$25 现在是全球定价的天花板。K2.6 用 $0.6/$4 拉出了一条独立曲线——输入价格是 Opus 的 1/8,输出是 1/6。国信证券的报告里讲得更直接:国产模型的综合价格是 Claude/GPT 的 1/5 到 1/30。
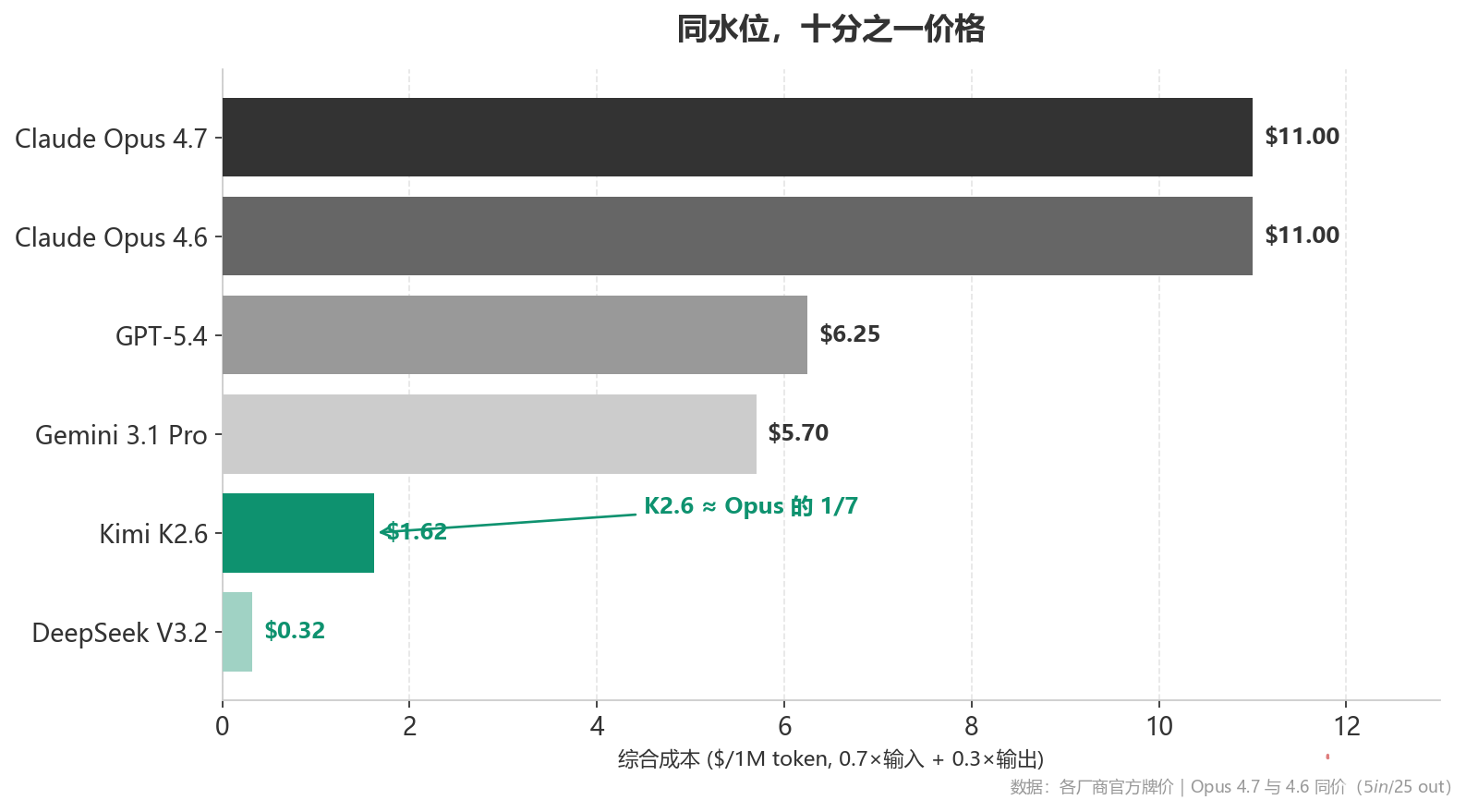
这意味着未来一两年 B 端企业选模型的逻辑,会被重写——不再是”哪家最强”,是”哪家最适合我的这个具体任务 × 预算”。
至于 Kimi 自己,这条路还很长。
长程编码、300 agent Swarm、12 小时连续执行——这些能力放在 demo 里很漂亮,放在真实企业场景里还要被时间和成本反复锤打。K2.6 也许下一次迭代会碰到瓶颈,也许会被 Opus 4.8、GPT-5.5 重新拉开。没人能替它做这个承诺。
但有一件事是确定的:
那个最会写的 AI,决定不写了。它选择了一条更孤独、也更难走的路——不再讨好所有用户,只服务那些愿意把 12 小时任务交给它的工程师。
在 2026 年的春天,国产模型里,有人第一次敢这样做选择。
你最近是继续在用 Kimi,还是已经切到别家了?在评论里聊聊你的选择。