
Claude Opus 4.7 实测体验:凌晨发布的「最强打工人」

Claude Opus 4.7 实测体验:凌晨发布的「最强打工人」
一、旧金山早上八点发版的 Opus 4.7
4 月 16 日晚上 11 点,北京的深夜;旧金山那头,时钟刚刚拨到早上 8 点整。
Anthropic 没有搞 Keynote,也没有倒计时预告,一则博文、一条 API 更新,Claude Opus 4.7 就这么上线了。时间点倒挺有意思——加州的工程师们刚刷完牙喝上第一杯咖啡,版就发出来了☕。太平洋对岸的我们,则是顶着黑眼圈守着更新日志刷到后半夜。
(调侃一句:这家公司每次大版本都是旧金山早高峰刚结束就发。我怀疑不是巧合,是”趁老板还没进会议室”的产品节奏学🤫。)
这次的升级口径,官方一句话概括得很克制:
“Opus 4.7 是对 Opus 4.6 在高级软件工程能力上的显著改进。“(Anthropic 官网)
翻译成人话就是——你之前不敢扔给它的硬活,现在可以扔了。
但别只看这句话。读完系统卡和合作伙伴反馈后你会发现,这次升级的”水下冰山”远比 Anthropic 自己说的大——自我验证(self-verification)、视觉分辨率翻三倍、多步 Agent 成功率 +14%,每一条拿出来都够写一篇文章。
二、价钱没涨,但账单可能会涨
很多人第一反应是看钱包:
| 模型 | 输入 | 输出 |
|---|---|---|
| Opus 4.7(新) | $5 / 百万 tokens | $25 / 百万 tokens |
| Opus 4.6 | $5 / 百万 tokens | $25 / 百万 tokens |
| Sonnet 4.6 | $3 / 百万 tokens | $15 / 百万 tokens |
| Haiku 4.5 | $1 / 百万 tokens | $5 / 百万 tokens |
官方单价一分未涨,仍然是 Opus 4.6 的档位;Sonnet 和 Haiku 也没动。看似皆大欢喜,但这里有一个很容易被忽略的坑——
👇 这是我在 Claude Code 里切换模型时看到的提示:
Opus 4.7 · Most capable for complex work · ~2× usage vs Sonnet
“2× usage vs Sonnet”,是官方自己承认的事实:Opus 4.7 更换了新的分词器(tokenizer),对同一段文字的切分更细,token 数最高会多出约 35%,叠加 Opus 本身就比 Sonnet 贵,算下来同一项任务的账单大约是 Sonnet 的两倍。
Anthropic 官方原文写得很坦诚:
“同样的输入在新分词器下可能映射为更多的 token——大约是 1.0× 到 1.35×,取决于内容类型。”
换句话说,单价没涨,但 Opus 4.7 在”数 token”这件事上变得更”贪”了。所以 Anthropic 这次给 Pro/Max 订阅用户的动作反而有意思:默认推荐仍是 Sonnet 4.6,Opus 4.7 只在”复杂任务”时提醒你用,并且在切换界面明晃晃地把”2ד标出来,相当于把成本控制的选择权重新交回给用户。
Hacker News 上有开发者吐槽:“现在跑一个 Agent loop,token 像水龙头一样哗哗流。” 但也有人反驳:“4.7 一次做对的事情,4.6 要反复改三四轮,算总账其实更便宜。“——这笔帐值得你在自己项目里实测一下(我感觉说的挺好)。
三、这次到底升级了什么
我把官网、VentureBeat、CNBC、The Next Web 几家的长文都啃了一遍,再对齐 Anthropic 官方系统卡,能被同时多家复述、可交叉验证的升级,大致是下面五件事:
1. 编码能力:SWE-bench 再跳一档
这是最硬的部分,也是 Anthropic 这次着重宣传的方向:
- SWE-bench Verified:80.8% → 87.6%
- SWE-bench Pro:53.4% → 64.3%(同场 GPT-5.4 是 57.7%,Gemini 3.1 Pro 是 54.2%)
- Terminal-bench 2.0:65.4% → 69.4%
- CursorBench:58% → 70%(这是 Cursor 编辑器内的实战测试,非实验室环境)
Rakuten 内部用自家的 Rakuten-SWE-Bench 测出来的结论更夸张——Opus 4.7 能解决的生产级任务是 Opus 4.6 的 3 倍,代码质量和测试质量都有双位数提升。
还有一条容易被忽略的:GPQA Diamond(研究生级别推理)从 91.3% 涨到 94.2%,这已经逼近人类专家上限了。
2. 自我验证:会自己写测试,自己打脸
这是我觉得最值得写进公众号开头的一条,但官方把它藏在系统卡中段。
“Opus 4.7 会主动想办法验证自己的输出再交卷。”
Anthropic 举的例子是:让模型从零写一个 Rust 的文本转语音(TTS)引擎,它写完之后自己把生成的音频喂给另一个语音识别模型做回译比对,确认输出没问题才说”做完了”。
在我自己的实测(后面第五节展开)里,这个行为非常明显:它不再是”写完就拍屁股走人”,而是会自觉跑一遍 verify,跑不过就回头改。
3. 代理能力:多步工作流 +14%,工具错误只剩 1/3
这条对用 Agent / Claude Code / 自建工作流的人最实在:
- 在复杂的多步工作流里,综合成功率相对 Opus 4.6 提升 14%;
- 同一批任务里,工具调用错误率只有原来的 1/3;
- 第一次通过 Anthropic 内部所谓的”隐式需求测试”——也就是不告诉它该用哪个工具,它自己推断。
合作伙伴的反馈更直观:
- Notion 的 AI 负责人 Sarah Sachs 说:“可靠性的跃升让 Notion Agent 感觉像个真正的队友。”
- Factory 反馈 Opus 4.7 在多步任务中成功率提升 10%~15%,工具错误更少,验证步骤执行更稳。
- Devin 甚至直接抛出一句**“能连续工作好几个小时,把难题啃下去,不会中途放弃”**。
- CodeRabbit 的代码审查评测显示,4.7 能发现更深层的 bug,给出的修改建议更连贯、更可操作。
4. 视觉能力:图像分辨率翻三倍
- 图片长边上限:1568px → 2576px(约 3.75 MP),Claude 史上第一次支持真·高分辨率图。
- Charts Reasoning(图表推理):69.1% → 82.1%,一次性涨 13 个点。
- arXiv 学术图表推理(带工具使用):84.7% → 91.0%。
实际意义就是,你现在丢一张真实的 Figma 设计稿、真实的 PPT 截图、甚至一张 A4 扫描件进去,它能读清楚边角的小字了。之前你得先裁切放大再喂给它的操作,现在可以省了。
5. 新推理档位 xhigh + Task Budgets
- 在原先的 low / medium / high / max 之间,官方新增了一档
xhigh(extra high),并建议——“编码和 Agent 类任务直接从 xhigh 起步”。在 Claude Code 中,所有方案的默认档位已经提升到 xhigh。 task_budgets(公测中):给整个 Agent 循环(思考 + 工具调用 + 工具结果 + 最终输出)一个总 token 预算,避免它”聊着聊着烧穿你账户”。
这俩新功能加在一起,某种程度上把 Opus 4.7 从”模型”推向了”Agent 基础设施”——Anthropic 不再只卖你一个 LLM,而是卖你一整套带预算、带效率档位的调度系统。
还有个小惊喜:Claude Code 新增了 /ultrareview 斜杠命令——专门开一个审查会话,通读你所有改动,像一个资深 reviewer 那样逐条挑 bug 和设计问题。Pro/Max 用户赠送 3 次免费额度。
四、一张雷达图看懂官方的七个维度
官方博文里那组切换标签的柱状图(办公任务 / 想象 / 文件推理 / 长语境推理 / 生物学 / 长期一致性 / 编码),在公众号里一张一张切图太散,我把七张图的数据汇拢成一张雷达图,只比较 Opus 4.7 vs Opus 4.6——两条线清清楚楚,哪里进步大、哪里几乎持平,一眼就能看出来。
为什么只放两条线? GPT-5.4 和 Gemini 3.1 Pro 在好几个维度官方没给数据(想象、长语境推理、生物学、长期一致性、编码这五个维度均无可比数据),硬塞进去会造成误导。所以雷达图保持纯净的”自家迭代对比”,GPT/Gemini 的已知数据放在下方独立表格里。
雷达图原始数据(各维度代表指标 + 原始值)
| 维度 | 测试基准 | Opus 4.7 | Opus 4.6 | 提升 |
|---|---|---|---|---|
| 办公任务 | GDPVal-AA(Elo) | 1753 | 1619 | +8.3% |
| 想象 | ScreenSpot-Pro(无工具,低分辨率,%) | 69.0 | 57.7 | +19.6% |
| 文件推理 | OfficeQA Pro(%) | 80.6 | 57.1 | +41.1% ⬆️ |
| 长语境推理 | GraphWalks Parents 1M(%) | 75.1 | 71.1 | +5.6% |
| 生物学 | Structural Biology(%) | 74.0 | 30.9 | +139.5% 🚀 |
| 长期一致性 | Vending-Bench 2(金钱均衡,$) | $10,937 | $8,018 | +36.4% |
| 编码 | SWE-bench Multilingual(%) | 80.5 | 77.8 | +3.5% |
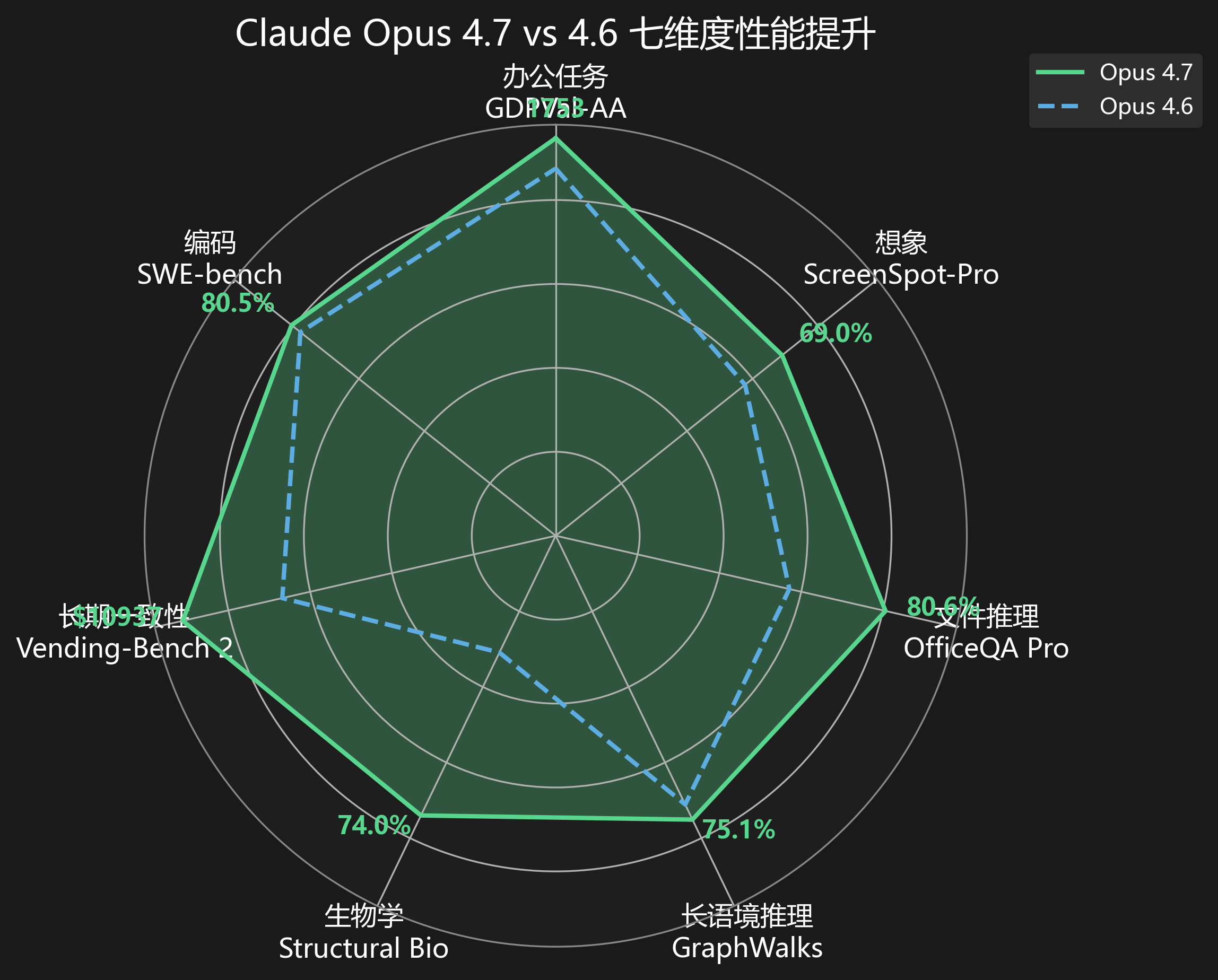
关于”想象”这一维的特别说明: Opus 4.7 新增了高分辨率支持,同一个 ScreenSpot-Pro 测试,4.7 高分辨率无工具拿到 79.5%(带工具 87.6%),而雷达图用的是低分辨率数据与 4.6 公平对比(57.7% → 69.0%)——高分辨率那条柱是 4.7 独有的,已没有对手的 baseline。
📊 GPT-5.4 / Gemini 3.1 Pro 官方对比数据
下面这张表是 Anthropic 官网直接给出的竞品数据——仅”文件推理”和”办公任务”两个维度有可直接对比的数字。其余五个维度,GPT-5.4 和 Gemini 3.1 Pro 均未公布同口径成绩,无法列入:
| 维度 | 测试基准 | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| 文件推理 | OfficeQA Pro(%) | 80.6 | 51.1 | 42.9 |
| 办公任务 | GDPVal-AA(Elo) | 1753 | 1674 | 1314 |
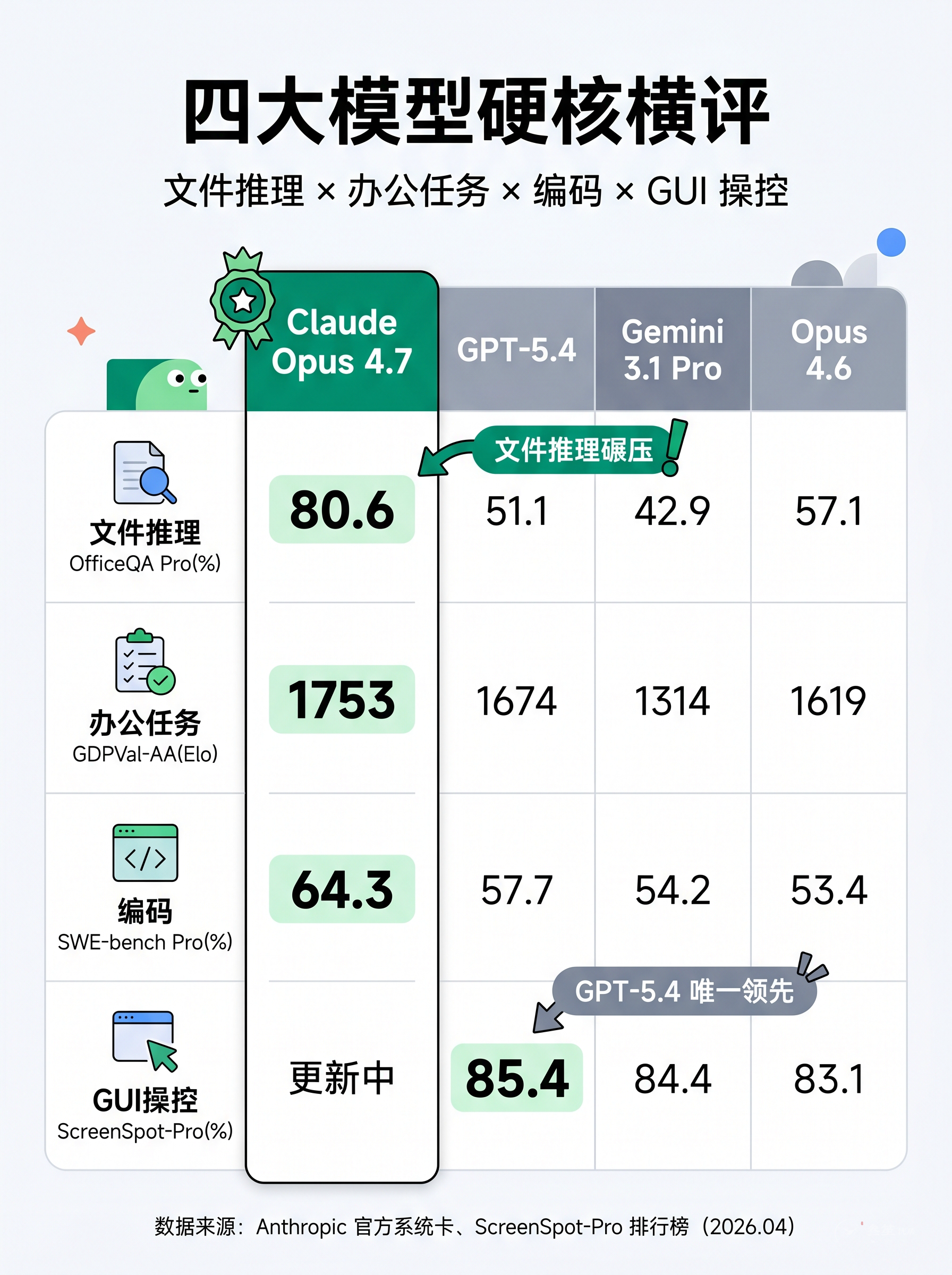
一眼结论:
- 文件推理是 Opus 4.7 本次最碾压的维度——80.6% vs GPT-5.4 的 51.1%(领先近 30 个百分点)、vs Gemini 3.1 Pro 的 42.9%(领先近 38 个百分点)。这意味着你扔一份复杂的 PDF 合同或一堆 Excel 报表进去,4.7 几乎是碾压级的理解力。
- 办公任务上 Opus 4.7 依然领先,但差距没那么夸张——1753 vs GPT-5.4 的 1674(仅差 4.7%),Gemini 3.1 Pro 则明显掉队。
💡 延伸参考: 在编码赛道上的另一个重要横评——SWE-bench Pro(专业级真实代码修复),Opus 4.7 拿到 64.3%,GPT-5.4 是 57.7%,Gemini 3.1 Pro 是 54.2%。虽然不在上面那组”七维度”里,但它可能是开发者最关心的单一指标。
💡 GUI 视觉操控: 在 ScreenSpot-Pro(专业桌面软件 GUI 定位)排行榜上,GPT-5.4 以 85.4% 暂时领先,Gemini 3.1 Pro 紧随其后 84.4%。这是 GPT-5.4 目前为数不多明确领先的领域之一。 Opus 4.6 在该榜单为 83.1%(Opus 4.7 数据尚在更新中)。
Anthropic 这次没有放出数字虐杀对手,反倒老老实实把每一项打到小数点后一位,甚至把自家预览版 “Mythos Preview” 的数据也放上来——SWE-bench Verified 93.9% 就是它。意思是:“4.7 已经不错,但我们自己内部还有更狠的。”
顺带一提,Anthropic 解释了为什么 Mythos Preview 不全面放开:它是目前安全对齐做得最好的模型,但网络安全能力也最强——Anthropic 选择先在 Opus 4.7 上测试新的安全护栏(Project Glasswing),积累经验后再逐步放开 Mythos 级别模型。简单说:不是它不能给你用,是它太强了,Anthropic 自己还没想好怎么安全地给你用。
五、实测:我让它复核自己兄弟写过的 Skill
光看榜单都是数字,没有体感。 我挑了自己手头最熟的一件事:让 Opus 4.7 来复核我的 sandy-write Skill 这套发布流水线——这活儿之前是 Opus 4.6 写的。
实测场景一:发现了 4.6 留下的断链

结论让我挺意外。Opus 4.7 在一次扫描里就标出了三类问题:
- 断链:多处
SKILL.md引用了references/music.md、scripts/generate_article_tags.py等已不存在的文件; - 配置分层错位:品牌 / 栏目 id / 主题色等耦合在
SKILL.md里,没有单独拆到brand.yaml和EXTEND.md; - “遗漏/反复/手动介入”的根因:根本问题是没有一个 checklist 用 DSL 自动断言,每次都是靠模型”记着办”——这当然会漏。
它没有直接改代码,而是给了我 A/B/C 三套改造方案,并按”代价 vs 收益”排了序。
实测场景二:真动手时,它会自己跑一遍看对不对

确认方案后,Opus 4.7 新增了 pipeline.py(418 行),把 init / status / next / verify / done 五个命令拉通成一条流水线;同时修了 SKILL.md 里的”恢复协议”段,排版顺序错误也顺手改了。
最让我有感觉的细节是——它改完之后主动说”我跑一遍 verify init 确认能跑通再交卷”,然后真的跑了,跑失败一次,自己查日志,改完再跑。这个”自我验证”动作,以前在 Opus 4.6 上我得显式写进 prompt 才能稳定触发,现在它默认会做。
实测场景三:和 Antigravity 吵架时的”认错”

我在 Claude Code 和 Antigravity 两边同时作业,两边 Agent 对同一套 Skill 的理解出现了分歧。有意思的是,Opus 4.7 在被打脸时不再硬撑:
“断链问题我确实漏了,重新核实后列出——不对,我之前的’纠正’也是错的,再重新核实一次。”
这种”连续自我修正 + 主动承认之前答错”的交互,在 4.6 上是偶尔会出现;到 4.7 变成几乎每次被挑战都会主动重新核对一遍事实,而不是给你一段”您说得对”的场面话。
Anthropic 官方在安全对齐评估中也印证了这一点——Opus 4.7 在抵抗奉承(sycophancy)和诚实度方面,比 4.6 有改善。它会纠正你,而不是顺着你说。我觉得Gemini 3.1pro这点比较明显,每次和他对话,他总会先表扬我一顿。
实测小结(体感,非严谨)
| 维度 | 4.6 体感 | 4.7 体感 |
|---|---|---|
| 扔硬活敢不敢睡觉 | 不敢,得盯着 | 敢(它会自己验证) |
| 指令执行精确度 | 偶尔”善意跳过” | 逐字执行,不自作主张 |
| 被打脸的反应 | 顺着说”您说得对” | 重新核事实、承认错 |
| 长链 Agent 任务 | 容易中途卡壳 | 能连跑一两小时 |
| Token 成本 | 基准 | 明显更贵(35% 起) |
开发者社区的一些零散体感补充(来自 Hacker News / Reddit / 各技术博客,发布后 24 小时内):
- “在 Cursor 里用 4.7 重构一个跨文件的 TypeScript 项目,一次跑通的概率明显变高了。以前同样的任务要 Continue 三四次。”
- “指令遵循变严了,我以前写得比较模糊的 prompt 现在反而出问题——4.6 会帮你脑补,4.7 直接按字面执行。老 prompt 可能要重新调一下。”
- “有时候感觉它’过度严谨’了,会卡在一个验证步骤反复跑,token 刷刷地烧。”
- “Memory 能力确实有感:跨 session 的任务接续比以前顺,不需要每次都重新给一遍上下文。“
六、国内用户的几个现实问题
这部分我不打算回避,因为评论区一定会问:
1. 官方定价没涨,但 Token 账单会涨 30%~100%
老项目迁移前先在测试环境跑一遍再决定是否切。Anthropic 自己也建议”在真实流量上实测差异”。
2. 身份验证更严
Anthropic 这次顺手收紧了地区合规和实名制,国内订阅 / API 使用确实在经历一波”断供”风波(LINUX DO 和爱范儿都有详细报道),走第三方代理的朋友要留意风控。这次 Opus 4.7 也是首个搭载 Project Glasswing 安全护栏的模型——会自动检测和屏蔽高风险网络安全请求。正经做安全研究的需要申请 Cyber Verification Program。
3. 国产替代的位置
单看 SWE-bench Pro 这一项,GLM-5.1(58.4%)已经超过了 Opus 4.6(53.4%)甚至 GPT-5.4(57.7%),千问 3.6-Plus 也拿到 49.5%。但基准分数和综合体感是两回事——我自己同时用过这几家,在长链 Agent 任务的稳定性、指令遵循的精确度、以及”出了错会不会自己发现”这些维度上,国产模型和 Opus 4.7 之间的差距比跑分显示的要大。单项不代表全面,对”能不能一次做对、能不能自己验证”这件事极端敏感的场景,Opus 4.7 仍然是我手上最稳的那张牌。
4. 用还是不用的决策树
- 日常对话 / 简单文本生成 → Sonnet 4.6 甚至 Haiku,别浪费钱
- 跨文件代码重构 / 复杂 Agent 任务 → Opus 4.7 + xhigh 档位
- 高分辨率图表解读 / PDF 分析 → Opus 4.7(视觉提升最明显的场景)
- 预算紧张但需要 Opus 级能力 → 试试模型路由:简单步骤走 Sonnet,关键步骤走 Opus
七、写在最后:它不再像工具,而更像一个会自证的同事
用了一晚上,我最直观的感受是:
Opus 4.6 交付的是”代码”,Opus 4.7 交付的是”已经自己验证过的代码”。
这中间的差别,看起来只差一个 verify 步骤,但对我这种”把 Claude 当队友用”的工作流来说,节省的是我反复回头检查的那部分心智——我不用再时刻盯着它有没有耍滑头、有没有”善意地”跳过某行指令,它会自己跑一圈证明给我看。
Anthropic 官方说得好:“用户可以把以前不敢放手的硬活,现在安心交给 Opus 4.7。” 我实测下来的结论是——他们没有夸大。
价格没变、分词器更贵、限流更严——这些都是小账。 大账是:这次升级把”AI 辅助编程”往”AI 独立承担编程”的方向又推了半步。
🎩 送走老板的一句话:“这次 Anthropic 没给你新魔法,它给你的是一个愿意自证清白的员工。”
如果这个员工能值每百万 token 25 刀的出货价,那真的,香。


📎 信息来源
- Introducing Claude Opus 4.7 — Anthropic
- What’s new in Claude Opus 4.7 — Claude API Docs
- Claude Opus 4.7 is generally available — GitHub Changelog
- VentureBeat:Anthropic 窄幅夺回”最强公开 LLM”
- The Next Web:SWE-bench 与 Agent 推理领先
- CNBC:Opus 4.7 发布(对比 Mythos)
- Vellum AI:Opus 4.7 Benchmarks Explained
- CodeRabbit:4.7 对 AI Code Review 意味着什么
- 36 氪:Claude Code 一夜重构,7×24 替你打工
- 爱范儿:Opus 4.7 将上线,但 Anthropic 要查你证件
- ABMedia 动区:Opus 4.7 完整评测