
我让 Claude Code 给自己做了一份「私人 BI」


我让 Claude Code 给自己做了一份「私人 BI」
昨晚我对着电脑敲了一句话。
「分析我公众号最近一个月的所有文章数据,告诉我哪些是顶部、哪些是腰部断层、哪些时段更容易爆。顺便,把小宇宙那边的播客数据也拉过来一起对比。」
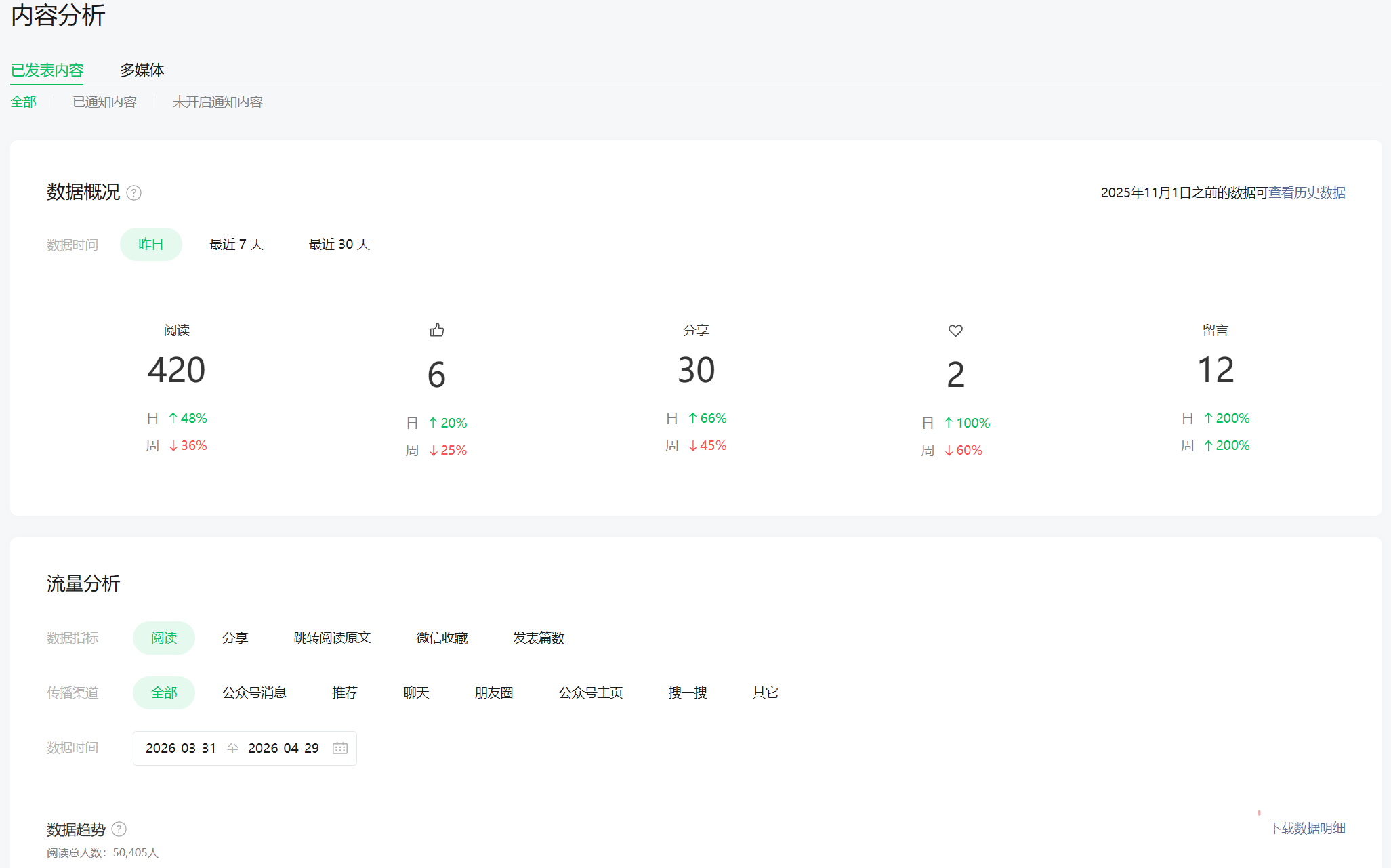
今天早上,桌面上多了一份 PDF。封面是品牌绿,里面 8 个维度、4 张柱状图、3 张折线图,标注着「周三是金日(均阅读 +47%)」「腰部断层有明显断点」「早安 AI 系列在小宇宙的完播率高于公众号在看率约 3 倍」。
这份报告,是 Claude Code 从我提供的 cookies 里自动拉数据、写脚本、生图、排版完成的。我全程没写一行代码——而且整套流程已经固化成一个专属 Skill,文末有领取方式。
顺便说一句:我并非 IT 人士。我所有从业经历都在传统行业——3 年房建、13 年房地产、1 年家装。3 个月前我才第一次打开 Claude。所以 AI 离你也不远——它正在做的事叫技术平权:把过去要懂代码才能做的事,变成只要会说话就能做。
这让我想到一个笑话——以前觉得要学 PS,还没学会,一键修图出来了;后来觉得要学视频剪辑,还没开始,智能一键成片出来了;现在觉得是不是该学点编程,结果 AI 直接帮你把项目跑通了。事实证明:只要你学得足够慢,最后就什么都不用学。
玩笑归玩笑。调侃背后是一个真实在发生的事——AI 把技术门槛压到了一个谁都跨得过去的高度。
回到那份 PDF。
它的学名叫「私人 BI」——BI 是 Business Intelligence,中文「商业智能」,本质是一套把数据变成决策的系统。大公司花几十万买的 Power BI、Tableau 做的就是这件事。
而这件事的意义不是 AI 多强——是第三方数据工具花钱也买不到这种视角的报告,从今天起对我来说零边际成本。
第三方工具看不到的事
做自媒体的应该都用过新榜、西瓜数据、蝉妈妈、壹伴这类工具。它们都很好。但都有同一个毛病:你只能看到工具方让你看的东西。
先说官方后台。微信公众平台的数据中心,准、免费、实时,但维度有限——你看得到每天阅读量,看不到读者构成,看不清传播路径,不知道用户从哪个渠道来。导出能力又弱,想做长期趋势追踪,几乎不可能。
再说第三方平台。它们补上了官方缺的几块——竞品对比、行业排行、关键词热度。但它们有三个共同的天花板:
第一,指标是工具方定义的。 你想看「腰部断层」「周三金日」「同一篇文章在两个平台的完播差异」,工具方得先做这个功能,你才能看。它做了——是大众都在用的功能;它没做——你的问题永远没答案。
第二,跨平台割裂。 公众号一个工具,小宇宙一个工具,小红书又一个,微博又一个。每个工具只看自己那一摊数据。但创作者真正的问题往往是跨平台的——「同一篇内容、两个渠道,到底哪个更值得继续投入?」没有任何一个第三方工具能回答。
第三,永远不够个性化。 SaaS 的商业逻辑就是照顾大众,不会为单个用户做”你那个早安 AI 系列双平台对比”这种小众分析。
我做的晨报每天双发布到公众号 + 小宇宙。那个让我心痒最久的问题就是——同一份内容,两个渠道,听众的反馈到底差多少?谁更买账?
我翻遍了所有第三方工具,没有一个能回答这个问题。
划重点
- 官方后台:数据准,但维度有限,导出弱
- 第三方平台:补了竞品对比,但指标工具方定义、跨平台割裂、永远不够个性化
- 创作者最想问的”个性化、跨平台”问题,第三方都答不了

直到我意识到——做这件事其实不需要等工具方。我手里有自己账号的 cookies,cookies 就是私人 BI 的钥匙。
我让 Claude Code 做了什么
回到刚才说的「BI 个人化」这件事——具体是怎么发生的?
打个比方。第三方工具像外卖——好吃、方便、品类多,但永远是别人厨师的口味。私人 BI 像家里的小厨房——你想加多少辣、什么时候吃、要不要少盐,自己说了算。
把这间「数据厨房」搭起来,我做了三步。
我做了三步。
第一步,让 AI 把数据自动拉下来
旧做法是这样的:每周登微信公众平台后台,手动导 4 张 Excel,手贴进 Excel 表,手算字段。
新做法只有一步:把浏览器登录态 cookies 整段贴给 AI——就是那个 F12 里能看到的 cURL。AI 自己写 puller 脚本,每天跑一次,数据自动同步进 SQLite 数据库。
公众号 + 小宇宙各一个 puller 脚本。整个过程从”每周手动取数 2 小时”变成”5 分钟一次自动同步”。
第二步,让 AI 按 8 个维度分析
这一步有个常见的坑——直接让 AI 自由发挥写报告,大概率”幻觉”(编数据)。
正确的姿势是:让 AI 先写 SQL 查 SQLite,再让 AI 解读 SQL 结果。AI 是分析师,不是数据源。
我让它分析 8 个维度:
- 大盘趋势——粉丝、阅读、互动总量怎么走的
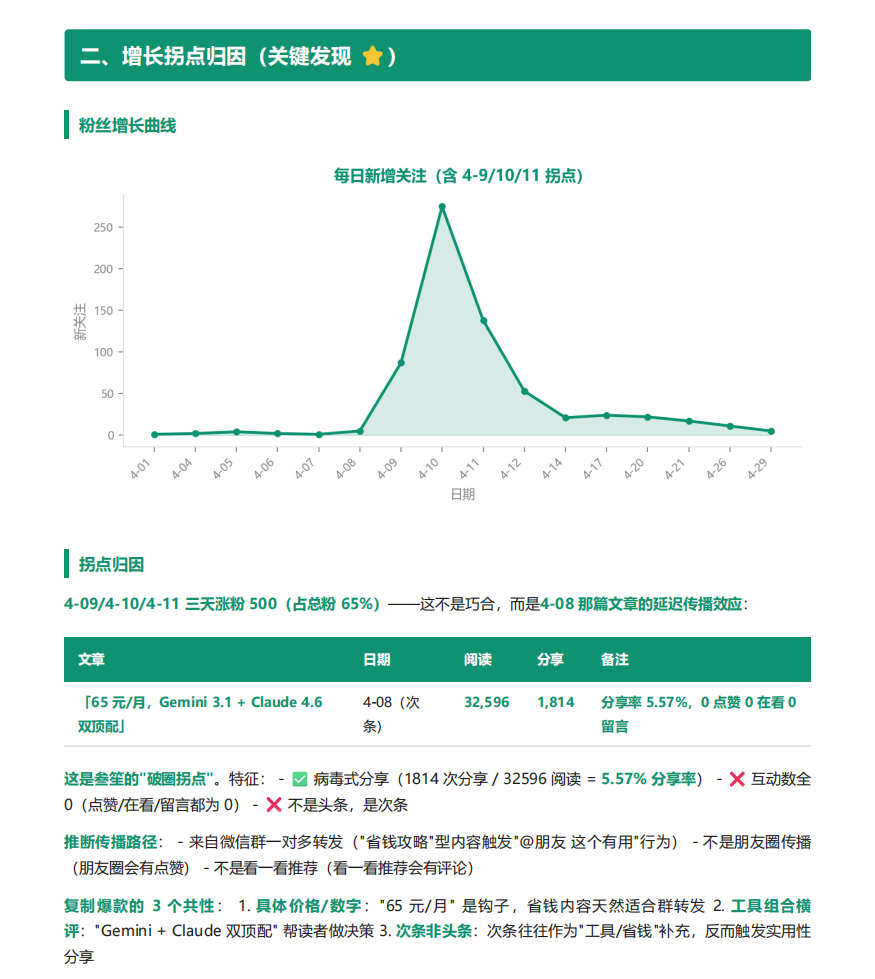
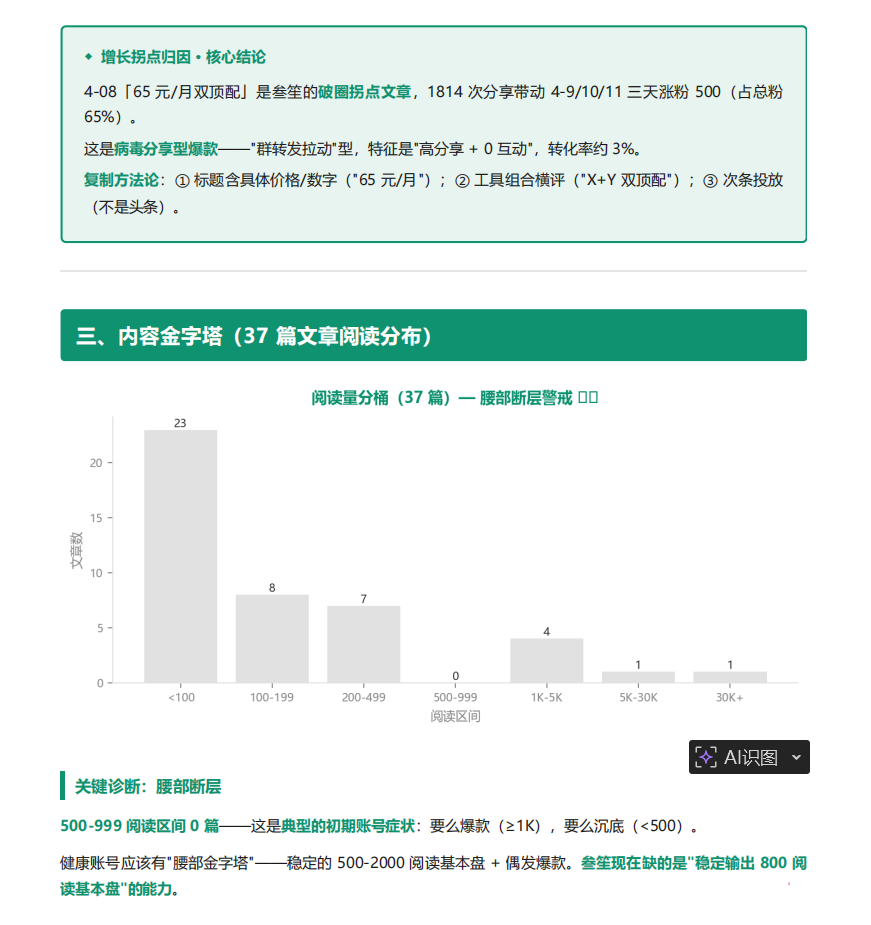
- 拐点归因——某天涨粉 / 阅读突变,是哪篇文章干的
- 阅读量金字塔——头部、腰部、尾部各占多少
- 互动质量——在看率、留言率、收藏率有没有反常
- 头条次条对比——次条数据系统性地比头条差多少
- 时间分布——周几发文最佳,几点最佳
- 新栏目效果——新开的小栏目数据怎么样
- 风险信号——哪些文章数据明显跌出区间,要警惕
第三方工具是”把数据塞给你,你自己看”。私人 BI 是”AI 看完数据,把判断给你”。
第三步,让 AI 出 PDF 报告
Markdown 写叙事 → matplotlib 渲染图表 → Chrome headless 打印成 PDF。统一品牌绿、统一字体、自动加封面。
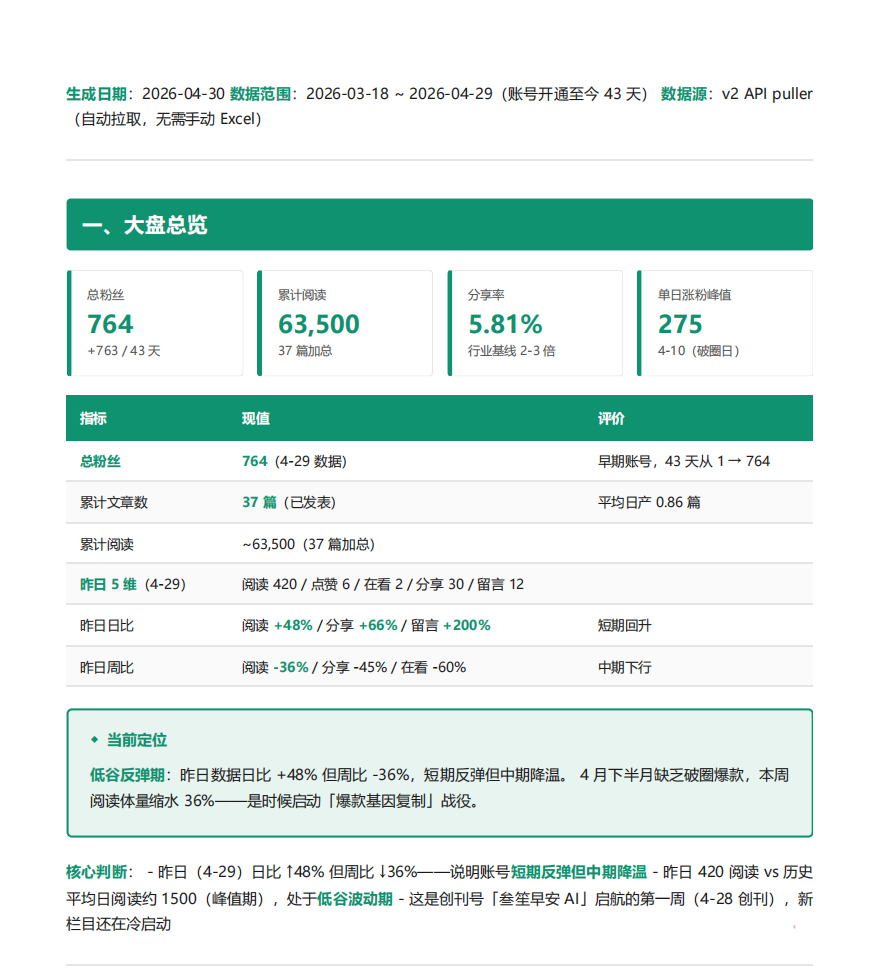
每周自动生成一份。相当于雇了一个全职的**“私人数据分析师”**,每周交一份 PDF 体检报告给我。
下面是一份真实跑出来的报告内页节选——

划重点
- 三步法:cookies 自动拉数据 → SQL+AI 分析 → matplotlib+PDF 出报告
- 关键诀窍:让 AI 先写代码、再做结论。绝不让它”凭印象给数字”
- 成本:0 元订阅费 + 4 小时一次性搭建
跨平台才是真核心
到这里你可能觉得”这不就是把 SaaS 重做一遍?”
不是。真正的差异化在跨平台。
第三方工具卡在”按平台分库”的设计里。你登录新榜只能看公众号,登录小宇宙后台只能看播客,登录新红数据只能看小红书。每个平台一份订阅、一个账号、一份独立的看板。
但创作者的问题往往是跨着平台问的——「同一篇内容,公众号和小宇宙哪个反馈更好?」「这个选题在小红书的传播量是公众号的几倍?」「我应该把更多精力放在哪个渠道?」
我用「早安 AI」这个日更系列做了一次双平台对比:
| 维度 | 公众号 | 小宇宙 |
|---|---|---|
| 主指标 | 阅读 / 在看率 | 播放 / 完播率 |
| 互动门槛 | 低(看完点在看) | 高(要听完整集) |
| 我的实际对比 | 在看率较低 | 完播率约为公众号在看率的 3 倍 |
完播率显著高于在看率,意味着——音频版本的”听众粘性”远高于图文版本的”读者粘性”。这个洞察直接决定了我接下来要把更多内容运营精力倾斜到哪个平台。
这个判断,任何一个第三方工具都给不了我。因为没有一个工具同时盯着两边的数据。
而且这套架构是可扩展的。任何一个有”登录态”的平台都能接进来。下一步我准备把小红书 + 微博也接进去——架构已经定好,无非是再写两个 puller。
更进一步:这份 PDF 现在是手动跑出来放桌面。下一步可以自动邮件发到我邮箱,或者机器人推到飞书工作台。这不是 PPT 上的概念,是已经具备技术条件的下一步。
不止是一份报告,是 24 小时的私人顾问
讲到这里,其实还有一层更值钱的差异——但我跟很多自媒体朋友聊的时候,大家都没意识到。
打个不那么严谨但很形象的比方。
第三方平台,像你花了一笔钱请咨询公司。咨询公司认真做了几周,交付一份精美的 PDF,里面有图表、有结论、有建议。读完你点头——很好,合作愉快。然后呢?然后就没有然后了。三个月后市场变了、平台规则变了、你的栏目调整了——那份报告慢慢就过时了,可它不会自己更新。
而 AI + 私人 BI,更像你雇了一个 24 小时在线的高级参谋。
它不只是给你交一份报告。它把你账号过去所有数据都装在脑子里——每篇文章的阅读、互动、来源、时段,每集播客的播放、完播、订阅曲线,都在它的上下文里。所以你随时可以问它:
- 「上周三那篇为什么沉了?」
- 「这个新栏目我连发 5 期都没起来,要不要砍掉?」
- 「下周我打算写’XX 主题’,你看历史数据,这种调性的文章在我账号里跑得怎么样?」
- 「同一个选题,你建议先发公众号还是先发小宇宙?」
每个回答都是带着你账号的数据上下文给的——不是大模型的通用建议,是定制建议。
而且不只是问答。聊到一半它发现需要补一个数据,它可以现场再去后台拉一次——比如你问「最近一个月互动率有变化吗」,它会自己去库里查一遍,如果发现库里数据是上周的,它会顺手再 pull 一次最新的,把数字接上来再给判断。
这是单纯”看一份报告”做不到的事——报告是结果,对话才是过程。
买报告,你买的是一次定格的判断。养一个私人 BI,你养的是一个跟着你账号一起长大的参谋。
我踩的 3 个坑
我不准备假装这事一气呵成。所有”自己造工具”的故事都伴随踩坑。藏起来不诚实,全讲又拖沓——挑 3 个最有故事感的。
但讲坑之前我先说一句最关键的:
下面这些坑听起来都很技术,但解决它们我没用过任何技术名词。我就是把现象原样发给 Claude——「我刚跑了一段什么,然后报错了,这是什么意思?」。Claude 会用大白话告诉我发生了什么,必要时还打比方。所以你看完只需要记住一件事:遇到任何看不懂的报错或异常,把它原样贴给 Claude,问它”这是什么意思、我该怎么办”——剩下的它会接住。
5 分钟撸了 1200 次 API,以为账号要被封
我写了一个并发脚本探接口,一个叫 datacubequery 的端点,5-8 分钟跑了 1200 次。
日志一刷,所有请求都返回”系统繁忙”。完了,账号炸了——我心里咯噔一下。
排查了 10 分钟才意识到:这是接口级软限流。微信公众号 backend 的限流是按 endpoint 设计的,不是按账号。也就是说——只对这一条 URL 节流,账号本身完全没事。
接口报错 ≠ 账号封禁。这是两件事。
教训是:遇到接口异常,先用另一个无关接口做交叉验证(比如文章列表接口),再决定要不要进”事故响应”模式。我那 10 分钟纯属白慌。
Chrome 偷偷把 HAR 导出按钮挪走了
抓接口的标准 SOP 是:浏览器 F12 → Network → 右键「Save all as HAR」。
这个流程稳定了 5 年。结果在 Chrome 147 里,右键菜单里找不到这个选项了——Google 把它移到了顶栏的下载图标。
我没主动验证当前版本,直接套老 SOP,让自己在那找了 5 分钟。
教训:涉及具体 GUI 操作的指引,先验证当前版本是否还是这个流程。AI 助理给的 SOP 也会过期——浏览器、办公软件这类高频更新的工具,任何”按钮在哪”的指引都要当成可能过期的知识。
跨平台 JOIN 没有共同 ID
公众号有 mid,小宇宙有 eid,两边都没有”我自己定义的 ID”。用什么把同一篇内容串起来?
我最后用了「软联结」:publish_date + 标题前缀(早安 AI%)——只对日更系列有效,对不规则发布的内容不行。这是个能用、但不优雅的方案。
教训:当数据没有唯一 ID 联结时,与其硬塞 ID 不如把”软联结的成立条件”写进文档——让未来的人(包括未来的我)一眼看明白这个 JOIN 在什么前提下可信、什么场景会失效。
把”软联结”伪装成”硬 JOIN”,才是更大的坑。
划重点
- 接口级软限流 ≠ 账号封禁:用无关接口交叉验证,别立刻进事故响应
- 浏览器 GUI 流程会过期:涉及”按钮在哪”的指引,先用最新版验证一次
- 没有共同 ID 时,把软联结的成立条件写进文档——比硬塞 ID 诚实
你也能这么做
到这里你大概知道这件事的边界了。如果你想自己上手——
文末回复邮箱领取我这份 skill 包(已脱敏)。包里默认配好了公众号 + 小宇宙两个平台的拉取脚本。拿到之后,3 步把它跟你自己的账号绑定。
前提认知:你不需要会编程。整个过程就是复制粘贴 + 跟 Claude 说话。 至于 Claude / 智能体本身的安装,网上有大量教程,这里就不再花篇幅讲了。下面假设你手里已经有一个能用的 Claude。
关键说明:你不需要重复我之前的探索过程。
我自己开发这套 skill 时,前后抓了 4 段不同接口的 cURL——文章列表、粉丝增长、每日汇总、单篇趋势——一段段研究该传什么参数、返回什么字段、入哪张表。这部分占了我整个工作 70% 的时间。
但 skill 打包好之后,这些”该拉哪几个接口、参数怎么传、字段怎么解析”全部已经固化在脚本里了。你拿到包,只需要做一件事——给它任意一段你自己后台请求的 cURL(一段就够,任意一条都行)。脚本会自己从里面提取 cookies 和 token,然后按内置清单挨个去拉数据。
我替你踩了坑、写了代码、固化了配方。你要做的只有”喂它一段 cURL”。下面就是这一动作的具体步骤。
第一步,绑定你的公众号
- 浏览器登录 mp.weixin.qq.com,扫码进后台
- 左侧导航随便点一个「数据分析」相关页面(内容分析、用户分析都行),让浏览器去拉一次后台数据
- 按 F12 打开开发者工具,切到 Network(网络)标签
- 按 F5 刷新页面,让请求都跑一遍
- 不需要搜任何关键词——Network 列表里随便找一条 URL 含
mp.weixin.qq.com/cgi-bin/或/misc/的 GET 请求(一般会有几十条,任意一条都行) - 右键 → Copy → Copy as cURL (bash)(必须选 bash,不是 cmd)
- 打开记事本 / VSCode 新建一个文件,粘贴整段进去,存成
wechat.curl.txt,放到 skill 包里的.cookies/文件夹下
💡 为什么不挑特定接口?因为 cookies 是后台共用的——任何一条后台请求的 cURL 都能让脚本拿到完整 cookies + token,不需要纠结具体哪个接口。

第二步,绑定你的小宇宙(没有播客就跳过)
- 浏览器登录 podcaster.xiaoyuzhoufm.com(前提是有审核通过的节目)
- 进入你的节目页
- F12 → Network → F5 刷新
- Network 上方搜索栏输入
getfd或podcaster-api,跳出一组对应请求 - 任意找一条点开,确认 URL 是
podcaster-api.xiaoyuzhoufm.com域名的请求 - 右键 → Copy → Copy as cURL (bash)
- 粘贴成
xiaoyuzhou.curl.txt,同样放到.cookies/文件夹
没有播客就跳过。Skill 会自动检测,缺哪个平台就跳过哪个。
第三步,跟 Claude 说一句话
在 skill 包目录里打开 Claude,说:
「跑一次我账号最近 30 天的诊断,8 个维度,出 PDF。」
剩下的 Claude 会自己接住:读 cookies → 调 puller 拉数据入库 → 按 8 维度查 SQL → 渲染 PDF 放在 reports/ 文件夹里。
第一次跑完,你桌面就有一份属于你账号的诊断报告了。
想改 skill?也是一句话的事
我那份 skill 给的是默认 8 个维度、默认报告样式。你完全可以让 Claude 帮你改——用自然语言就行,不用碰代码。
举几个例子——
想加竞品对比:
「再加一个维度,我想跟同领域的 5 个账号比:发文频率、爆款率、互动率。竞品账号是 X / Y / Z / W / V。」
想接小红书或微博:
「再帮我把这套逻辑接到小红书上,我账号是 @XXX。」
想改报告样式:
「报告太长了,以后每周给我一份 1 页摘要 + 1 页风险预警就够。详细数据保留在数据库里我自己查。」
想自动推送到邮箱:
「这份报告每周一早上 9 点自动发到我邮箱:XXX@XX.com。」
Claude 会自己改 puller、改分析逻辑、改报告模板——改完它会告诉你哪些文件被动了、跑通了没。
合规与能力边界
合规上:自己账号自己取的 cookies,只用来分析自己的账号数据——这是浏览器登录态的正常使用范围,完全合规。不要用别人 cookies 爬别人账号——既不合规,也跑不通(别人的 cookies 你也拿不到)。
能力上:
- 适合自己造:定制化分析、跨平台 JOIN、长期数据沉淀、报告自动化
- 适合买现成:实时舆情监控、爬竞品数据(SaaS 在合规和效率上更稳)、行业排行榜
私人 BI 不是要替代第三方工具。它是让你拥有第三方工具给不了的视角。
写在最后


回到开头那个画面——昨晚我对着电脑敲了一句话,今早 PDF 躺在桌面。
我做了 10 年地产,3 个月前才开始接触 AI。一开始我以为「AI 工具」就是 ChatGPT 帮我写一段文案。后来发现——真正的杠杆,是把 AI 当作”私人能力扩展器”。
它不替代专业分析师。它把”分析能力”白菜化到个人层。
每个会用 AI 的自媒体人,都可以拥有自己的 BI 系统、自己的数据分析师、自己的报告流水线。这件事的成本是 0 元订阅费 + 4 小时一次性搭建 + 一份不怕踩坑的勇气。
过去十年,“数据驱动”是大公司的奢侈品。今后十年,“数据驱动”是个人创作者的基础设施。
想要这份 skill 脱敏包?文末留言区留下你的邮箱 + 一句话告诉我你想拿它分析什么平台,我会统一发到你邮箱。
(备注:包里默认含公众号 + 小宇宙两个平台的拉取脚本,你需要按 README 里的步骤自己取一次账号 cookie 才能跑起来。其他平台的 puller 我后续会陆续补上,目前不在包里。)