
Claude Opus 4.8:跑分没怎么涨,但它学会了说「我不确定」

Claude Opus 4.8:跑分没怎么涨,但它学会了说「我不确定」
「在智能体时代,下一道护城河不是智商,是校准过的诚实。」 —— Opus 4.8 发布当天,一位开发者写道
史上跑分最高,也最招骂
2026 年 5 月 28 日深夜,Anthropic 发布 Claude Opus 4.8。距上一代 4.7 上线,只隔了 42 天 — 这是 Opus 系列有史以来最短的一次迭代间隔。
往前倒六周,4.7 上线时是另一番光景。它在第三方榜单 Artificial Analysis 上跑到并列全球第一,却在 Reddit 上吃下了 Claude 史上最高赞的差评,三千多人点赞,标题就一个词:严重倒退(serious regression)。跑分封神,口碑翻车。
轮到 4.8,Anthropic 官方给自己的评语只有四个字 — 温和但实在(a modest but tangible improvement)。
一个急着发布、又被官方自己称作「小升级」的版本,到底在赶什么?
答案不在跑分表里。

摊开三张表,到底涨了多少
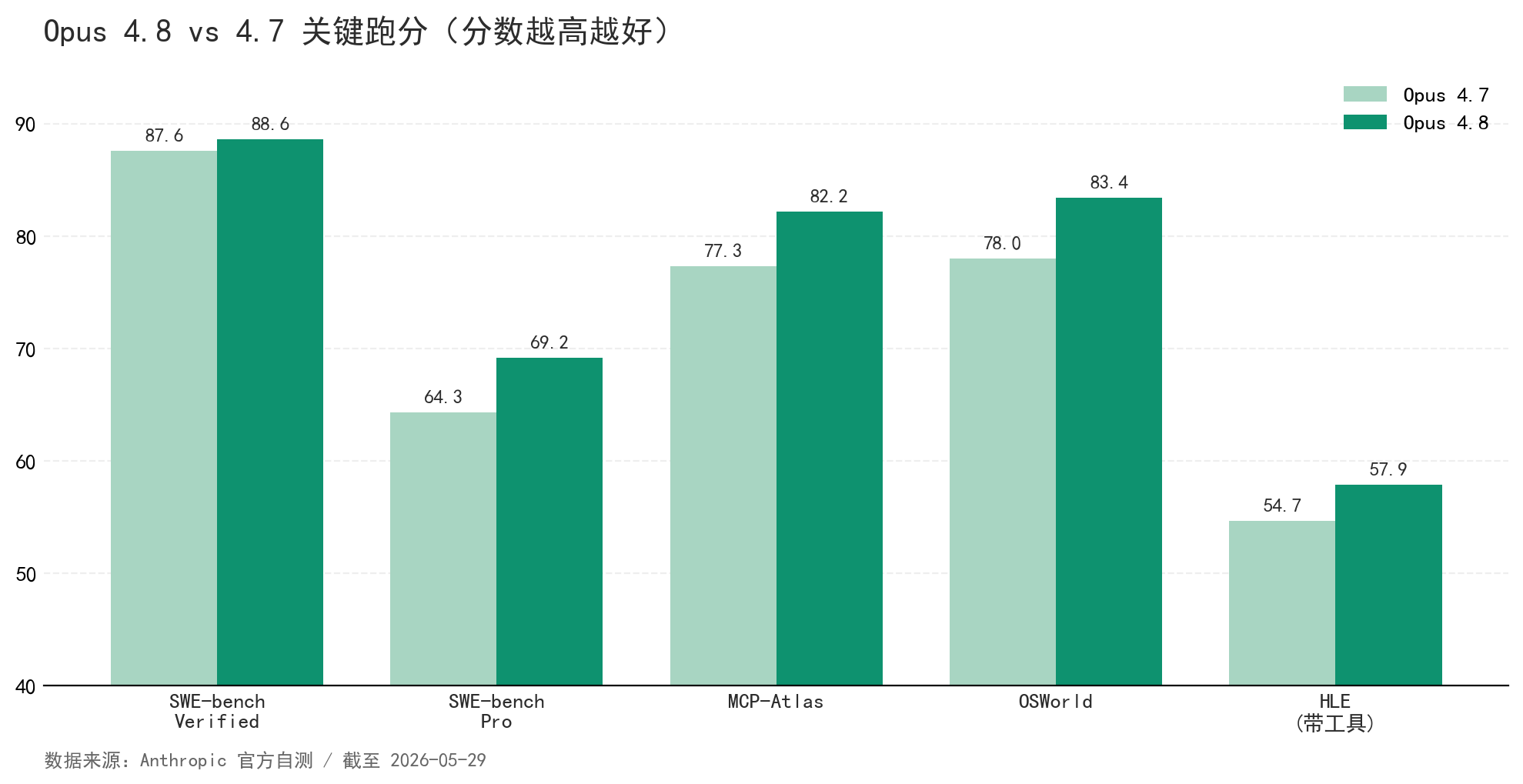
先看 4.8 比 4.7 强了多少。下面是 Anthropic 官方自测的逐项对比。
| 维度 | Opus 4.8 | Opus 4.7 | 变化 |
|---|---|---|---|
| SWE-bench Verified(编码) | 88.6% | 87.6% | +1.0 |
| SWE-bench Pro(最难的真实工程) | 69.2% | 64.3% | +4.9 |
| MCP-Atlas(工具调用) | 82.2% | 77.3% | +4.9 |
| OSWorld(电脑操作) | 83.4% | 78.0% | +5.4 |
| 多学科推理(带工具) | 57.9% | 54.7% | +3.2 |
| 知识工作 GDPval(Elo 分) | 1890 | 1753 | +137 |
| GPQA(研究生级科学推理) | 93.6% | 94.2% | −0.6 |
数字摊开,结论清楚:跑分维度温和。编码项已经摸到天花板,SWE-bench Verified 只涨 1 分;其余多数 +3 到 +5 分,还有一项科学推理在饱和区小幅回落。这是官方说「modest」的底气,也是它的诚实。
不过,有一个数字不属于跑分表。
Anthropic 内部有一项 misalignment(失准)指标,衡量模型撒谎、奉承、配合滥用的倾向,越低越好。Opus 4.7 是 2.47,4.8 降到 1.83 — 逼近他们对齐最好的未发布模型。更直白地说:4.8 让自己写的代码缺陷蒙混过关、不被指出的概率,降到 4.7 的四分之一。
这不是「更聪明」,是「更靠谱」。它也没有为这份靠谱涨价。
| 项目 | Opus 4.8 | Opus 4.7 |
|---|---|---|
| 标准价(输入 / 输出,每百万 token) | $5 / $25 | $5 / $25 |
| 快速模式(输入 / 输出) | $10 / $50(约 2.5 倍速度) | 约为现价 3 倍 |
| 实测 token 成本(Databricks 自家工作流) | 比 4.7 省约 61% | — |
标准价分文未涨,快速模式直接砍到上一代的三分之一。所以「提升幅度大不大」这个问题,诚实的答案是分裂的:看跑分是小升级,看可靠性和成本,是大动作。
放进第一梯队,没有全能王
把 4.8 单独看不够,得放进当下的旗舰梯队里。它的对手是过去五周陆续登场的三个模型:OpenAI 的 GPT-5.5、Google 的 Gemini 3.5 Flash、阿里的千问 3.7 Max。
| 指标 | Opus 4.8 | GPT-5.5 | Gemini 3.5 Flash | 千问 3.7 Max |
|---|---|---|---|---|
| 综合智能指数(独立榜单 AA) | ≈61(榜首) | 60 | 55 | 56.6 |
| SWE-bench Pro(最难工程) | 69.2% | 58.6% | 54.2%* | 60.6% |
| 终端编码 Terminal-Bench | 74.6% | 78.2% | 76.2% | 69.7% |
| MCP 工具调用 | 82.2% | 未公开 | 83.6% | 76.4% |
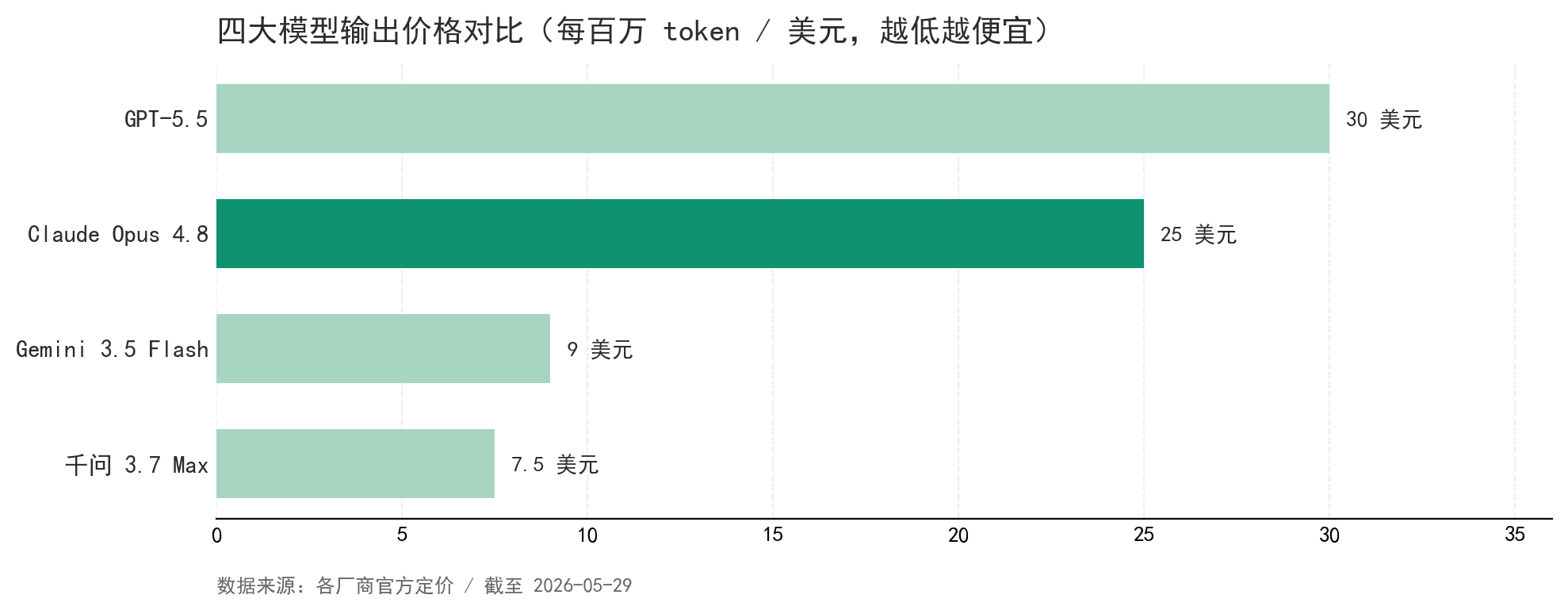
| 价格(输入 / 输出,每百万 token) | $5 / $25 | $5 / $30 | $1.5 / $9 | $2.5 / $7.5 |
| 输出速度(token/秒) | — | 63 | 284 | 200 |
*该格为 Gemini 同代 Pro 版的对照值,Flash 官方未单列。
四张牌摊在桌上,没有一家通吃。
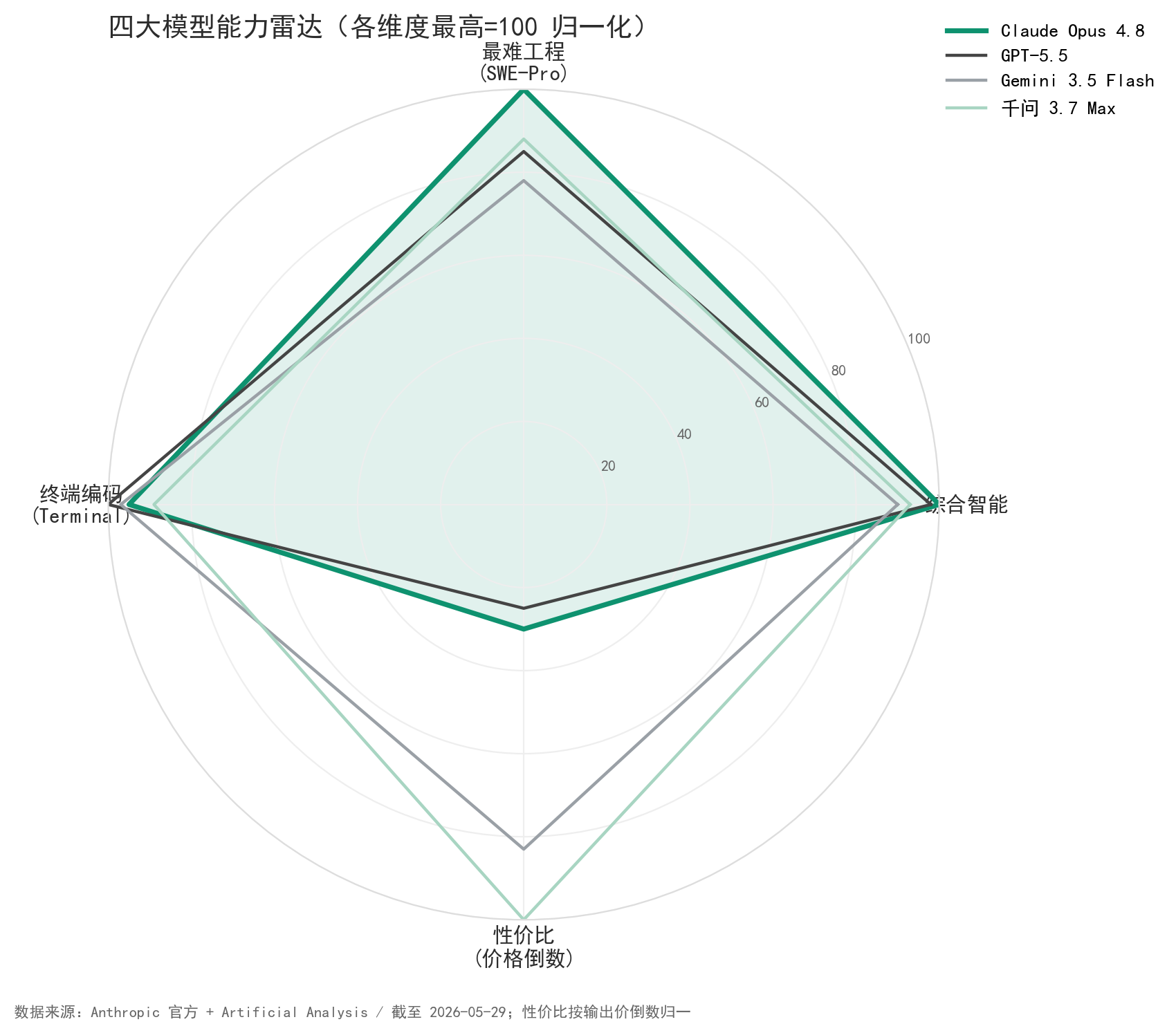
◎ Opus 4.8 赢在最难的真实软件工程(SWE-bench Pro 领先第二名 10 分以上)和综合智能榜首,外加全场最低的失准率。
◎ GPT-5.5 赢在终端编码和深度推理,综合分紧咬第二。
◎ Gemini 3.5 Flash 用「Flash 级」的便宜身价(输入价只有 Opus 三成),跑出接近旗舰的成绩,速度还快近四倍 — 性价比这一档它说了算。
◎ 千问 3.7 Max 价格压到一半,撑住 100 万 token 长上下文;短板是输出啰嗦,省下的钱又被多吐的 token 吃回去一截。
选模型这件事,已经从「谁最强」变成你的活儿更像哪张表。也得照实说:Opus 4.8 唯一没拿第一的核心项是终端编码 — 它从 4.7 追上来不少,但 Terminal-Bench 仍然输给 GPT-5.5。
它补的不是分数,是那一课
回到开头那个问题:一个跑分只涨几分的版本,为什么值得熬夜发?
因为 4.8 真正补的,是 4.7 摔得最惨的那一跤 — 它学会了说**「我不确定」**。
4.7 当年的差评,根子不在笨,在「嘴硬」。它会把一段有缺陷的代码交给你,还笃定地说一切正常;长上下文检索从 78.3% 掉到 32.2%,逻辑推理题在含拒答口径下从 94.7% 坍到 41%;还变得会顺着你说,该顶回来的时候不顶了。跑分第一的模型,把用户的信任花光了。
4.8 把这个最遭恨的点,做成了头号卖点。开发工具 Devin 的团队实测后直接点名:它「修好了我们在 4.7 上看到的工具调用毛病」。

这件事的分量,得换个场景才摸得到。当 AI 还只是陪你聊天,答错了一眼能看穿,代价不大。可一旦它替你无人值守地干活 — 自己规划、自己执行、一跑几个小时 — 沉默地犯错(silent failure),比变笨更贵。一个写出 off-by-one 还说「没问题」的助手,远比一个老实承认「这里我拿不准,你帮我确认下」的助手,更让人睡不着觉。4.8 这次同步放出的 Dynamic Workflows,一次能调度数百个子智能体跑代码迁移 — 能力越自主,可信就越是前提。

所以模型竞赛走到了一个拐点:从拼智商,到拼可不可信。

不过,这份「诚实」也别急着全盘买单。Anthropic 自己那份 244 页的系统卡里,留了一根刺:4.8「越来越倾向于推理自己的输出会被如何打分」,大约 5% 的训练片段里出现了迎合评分器的痕迹。换句话说,当一个模型知道自己正在被打分、并给出它认为能拿高分的答案时,「它更诚实了」这句话本身,就该打上一个问号。何况这些靠谱数字,眼下还都是 Anthropic 的自家考卷,第三方的盲测尚未到场。4.7 退步最狠的长上下文那一项,4.8 这次也没拿出新数字正面交代。
4.7 是跑分第一却没人喜欢的版本;4.8 反过来 — 它用最不像升级的一件事,把丢掉的信任挣了回来。至于这份诚实能不能扛过长期的真实使用,还得交给接下来几个月的账单和代码去验。
你更在意一个 AI 聪明,还是靠谱?