速递--GPT5.5发布及横向对比


速递—GPT5.5发布及横向对比
导读: 2026 年 4 月 23 日,OpenAI 正式发布 GPT-5.5(代号 Spud),一次性拿下 14 项 benchmark SOTA。与此同时,MiniMax M2.7、Claude Opus 4.7、Kimi K2.6、GLM-5.1、Gemini 3.1 Pro 也在最近 12 天里集中交卷。这篇文章我不讲情绪,只把核心参数、跑分、柱状图、雷达图、一线用户反馈、普通人决策建议——全部摊开给你看。
这两周 AI 圈子有点挤。
Anthropic 先起的头,4 月 17 日扔出 Claude Opus 4.7,两份最被盯着看的公开榜单一起登顶。三天后,Moonshot 那边 Kimi K2.6 开源放出,直接把自己架在 Claude Opus 4.7 旁边比划。同一周里,GLM-5.1 把火山方舟的 Coding Plan 填满了,MiniMax M2.7 以 $0.53 每百万 token 的 blended 价把国产阵营的性价比推到了一个之前没有过的位置。四家厂商,四把刀,彼此不客气。
然后 4 月 23 日,OpenAI 收尾。
GPT-5.5 正式发布,代号 Spud,土豆。Greg Brockman 在发布会上用他一贯不太激动的语气说,这是”两年研究成果”,是”我们思考模型开发方式的根本性转变”。总裁亲自下场定调的时候,你知道这事不小。
这篇文章不打算讲情绪。一周之内六个旗舰同时交卷,每家都在说自己赢了——我觉得对普通人来说,最有用的一件事是把对比表摆在你面前,让你自己看清楚每家到底赢在了哪、贵在了哪、适合谁。
所以接下来我会先讲时间轴和阵型,再用一张表把参数和价格摆出来,再用一张表把跑分摆出来,再把这两天一线用户的真实反馈整理一下,最后给你一个”如果你是 XX 人,就选 XX”的清单。
一周六个旗舰的阵型
先把这一周摆一下。这很重要,因为 GPT-5.5 不是一个人发布的——它是在一个所有人都刚交卷的考场里走进来的。
4 月 12 日,MiniMax M2.7。 开源,自进化 Agent 模型,主打低价。SWE-Pro 56.22,Terminal-Bench 2.0 57.0。blended 价做到 $0.53/M,是全场最便宜的旗舰。
4 月 17 日,Claude Opus 4.7。 Artificial Analysis 综合智能指数 57 分,和 GPT-5.4、Gemini 3.1 Pro 并列第一。Arena.ai 的 Code Arena 榜单单独登顶,HTML 和 React 两个子榜也拿第一。Anthropic 自己披露的数据说,在他们内部 93 项编码基准上,Opus 4.7 比 Opus 4.6 的任务解决率提升了 13%。这是一次稳扎稳打的迭代,不惊艳,但把企业客户要的每一个指标都往前推了一档。
4 月 20 日,Kimi K2.6。 开源,MoE 架构,总参数 1T,激活 32B,256K 上下文。月之暗面这次的路线写得很直——不跟闭源拼中文写作,不跟 GPT 拼聊天体验,直接打”开源编码 SOTA”。官方案例里 Kimi K2.6 在一台 Mac 上连续执行 12 小时以上、发起超过 4000 次工具调用、重构一个运营 8 年的金融撮合引擎,最终把中位吞吐量提升了 185%。你可以不信这个案例,但你不能不承认,开源模型第一次敢用这种工作量写官方博客。
同一周,GLM-5.1 把订阅制 Coding Plan 铺到了火山方舟,长程任务可以持续工作 8 小时。作为中文场景里最稳的那一档开源模型,它不出风头,但一直在干活。
再加上此前已经在场的 Gemini 3.1 Pro。 ARC-AGI-1 跑到 98%、1M 上下文、126 tok/s 的速度依然是全场最快。谷歌不发新模型,靠着之前那一版继续守住长文档和多模态的那一块市场。
4 月 23 日,GPT-5.5。 14 项 benchmark 拿 SOTA,Artificial Analysis 综合智能指数第一次把 OpenAI 单独推回到第一名。
这就是 GPT-5.5 登场时的全场阵型。
我这么铺垫,是想让你先有一个感觉——GPT-5.5 的跑分漂亮,不是因为它一枝独秀,而是因为它在一个所有人都已经站好位置的考场里,把卷子交得更干净一点。
这两件事,意义不一样。
核心参数与价格
先看硬参数。这张表里的每一列,都直接关系到你要不要掏钱、掏多少。
| 模型 | 发布 | 上下文 | API $/M | 开源 |
|---|---|---|---|---|
| GPT-5.5 | 04-23 | 1M | 5 / 30 | 闭源 |
| GPT-5.5 Pro | 04-23 | 1M | 30 / 180 | 闭源 |
| GPT-5.4 | 03-06 | 1.1M | 2.5 / 15 | 闭源 |
| Claude Opus 4.7 | 04-17 | 1M | 15 / 75 | 闭源 |
| Gemini 3.1 Pro | 在售 | 1M | 4.5(blended) | 闭源 |
| Kimi K2.6 | 04-20 | 256K | ≈Opus 19% | 开源 |
| GLM-5.1 | 在售 | 203K | 2.15(blended) | 开源 MIT |
| MiniMax M2.7 | 04-12 | 205K | 0.53(blended) | 开源 |
(数据来源:各家官方文档 + Artificial Analysis 2026-04 价格快照)
三件事值得你注意。
第一件,GPT-5.5 的 API 价格是 GPT-5.4 的两倍。 上一代 $2.50/$15,这一代 $5/$30。OpenAI 自己的解释是——GPT-5.5 在 Codex 里比 GPT-5.4 少用约 40% 的输出 token,所以真实账单涨幅大概在 20% 上下,而不是翻倍。这个算法对不对得看你自己的工作负载,但至少在发布日这一天,定价层面 OpenAI 是明确抬了身价的。
第二件,Claude Opus 4.7 的价格依然很硬。 $15/$75,比 GPT-5.5 高一倍。Anthropic 的策略始终是”企业级定价”,不跟消费市场打价格战。要订 Claude Max 才有性价比。
第三件,国产三家把价格带拉得非常开。 GLM-5.1 $2.15、MiniMax M2.7 $0.53、Kimi K2.6 按套餐订阅。这个价格带意味着,你现在做一个每天几万次调用的中文内容生成流水线,API 月度成本可以压到 $200 以内——这个数字在一年前想都不敢想。
上下文窗口这一栏,国产三家(Kimi 256K / GLM 203K / MiniMax 205K)明显比国外三家(都是 1M)短。对普通人影响不大,但做长文档处理、代码库级别分析的话,这是一道分水岭。
谁在哪里赢了
参数是账本,跑分是实测。先用一张柱状图把这一周最关键的那条基准摆出来——编程长任务(Terminal-Bench 2.0),这是 GPT-5.5 这次最刺眼的赢面。
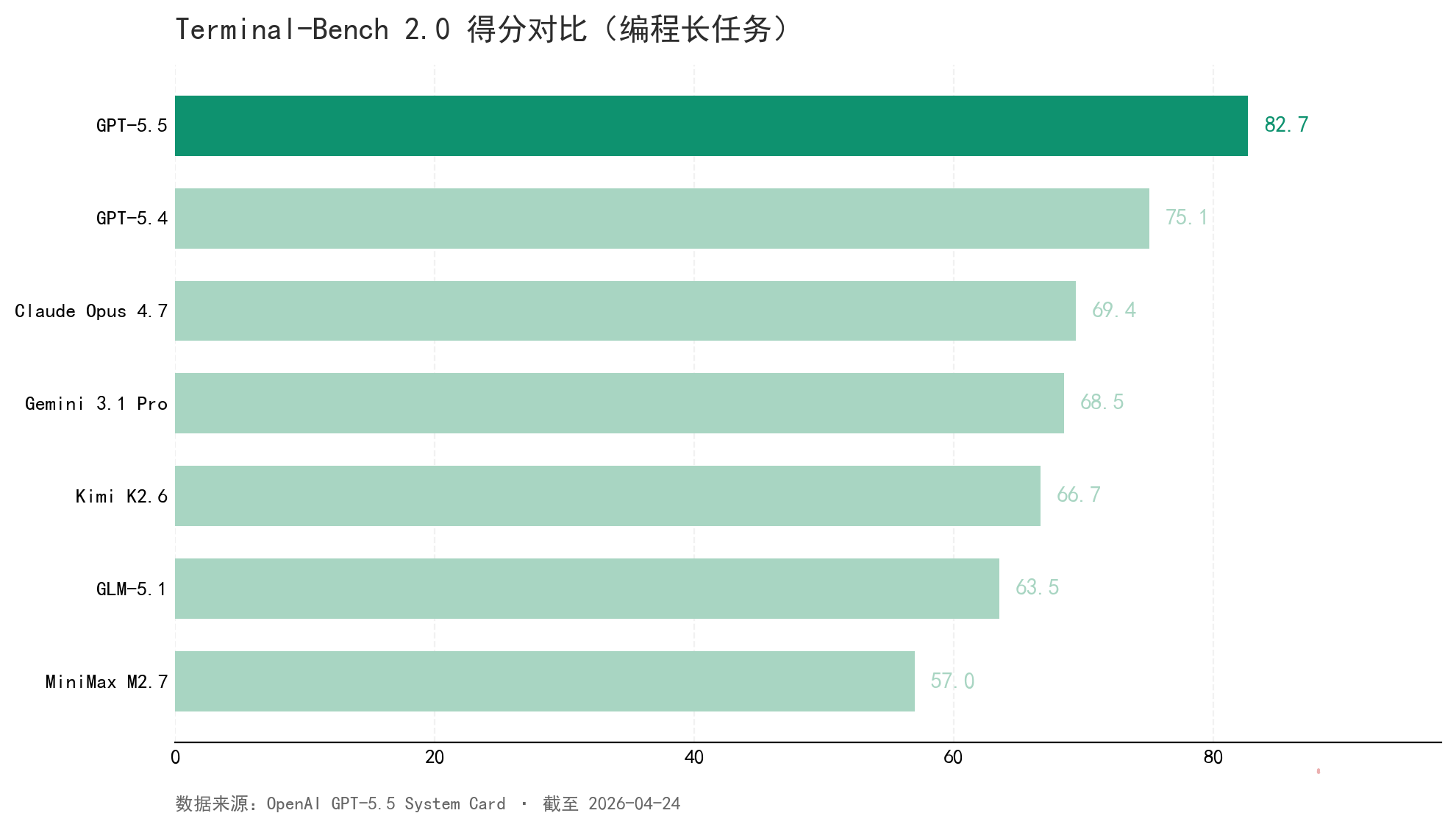
差距一目了然。GPT-5.5 在编程长任务这条线上,比过去一年一直占据主场的 Claude Opus 4.7 多出 13.3 个百分点。
再把国际四强(GPT-5.5 / GPT-5.4 / Opus 4.7 / Gemini 3.1 Pro)在 11 条主流基准上的分数并排摆出来——
| 基准(越高越好) | GPT-5.5 | GPT-5.4 | Opus 4.7 | Gemini 3.1 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7 | 75.1 | 69.4 | 68.5 |
| SWE-Bench Pro | 58.6 | 57.7 | 64.3 | 54.2 |
| FrontierMath Tier 4 | 35.4 | 27.1 | 22.9 | 16.7 |
| GPQA Diamond | 93.6 | 92.8 | 94.2 | 94.3 |
| ARC-AGI-2 | 85.0 | 73.3 | 75.8 | 77.1 |
| ARC-AGI-1 | 95.0 | 93.7 | 93.5 | 98.0 |
| OSWorld-Verified | 78.7 | 75.0 | 78.0 | — |
| BrowseComp | 84.4 | 82.7 | 79.3 | 85.9 |
| MCP Atlas | 75.3 | — | 79.1 | 78.2 |
| HLE 有工具 | 52.2 | 52.1 | 54.7 | 51.4 |
| AA 综合智能指数 | 60 | 56.8 | 57.3 | 57.2 |
(粗体 = 该行第一;”—” 表示官方未公布)
数字看着分散,我把四家的核心能力打在雷达图上——五个维度(编程长任务 / Agent 电脑使用 / 前沿数学 / 学术推理 / 网页检索),一眼就能看清每家守在哪一格。
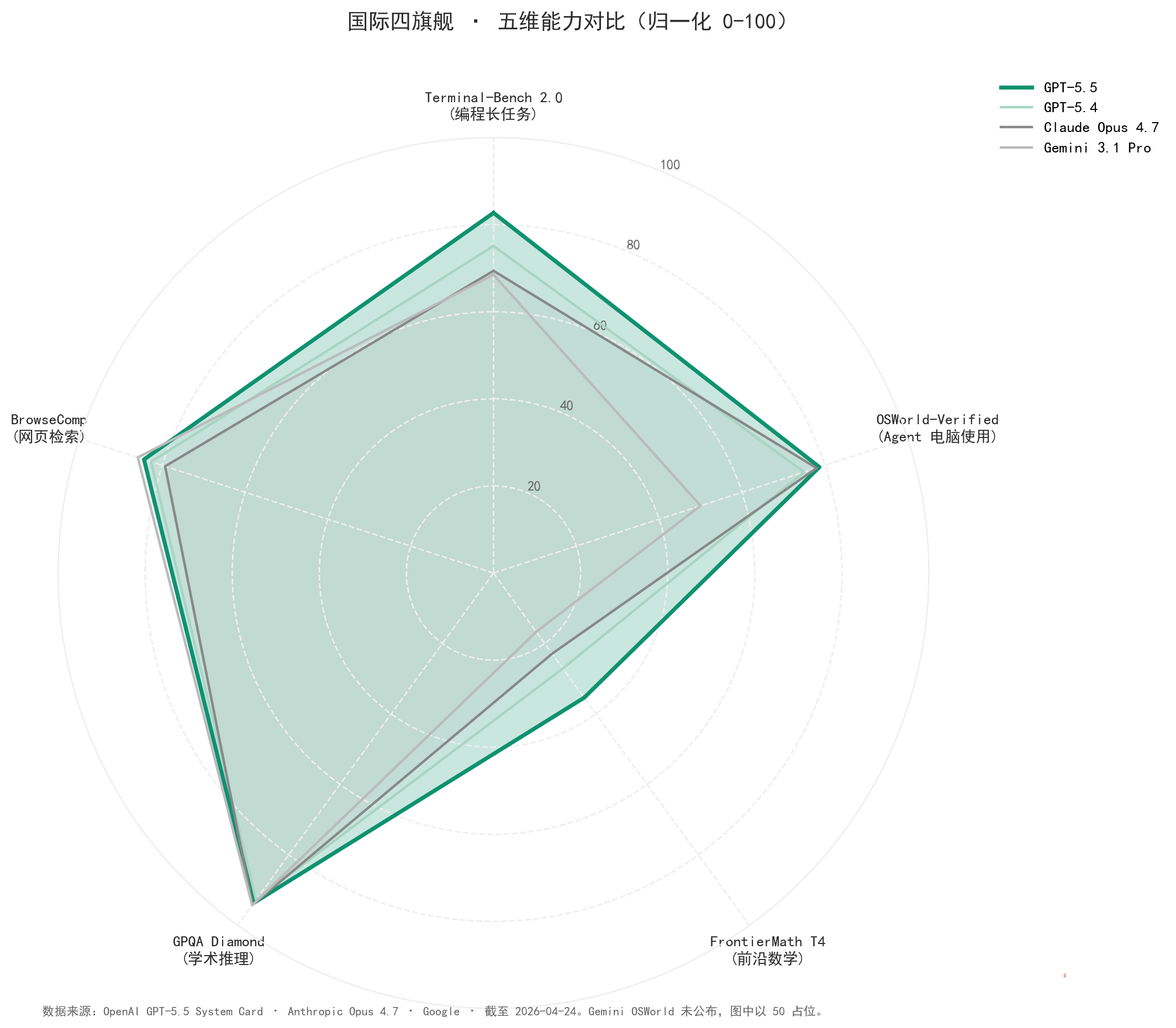
GPT-5.5 的轮廓外扩在右半圈(编程 / Agent / 数学),Opus 4.7 和 Gemini 3.1 Pro 在左半圈(学术 / 检索)更饱满。这不是”谁强谁弱”,是”各占一角”。
国产三家的跑分数据分散在几个主流基准上,我把和 GPT-5.5 直接可比的行单独摆成一张小表——
| 基准 | GPT-5.5 | Kimi K2.6 | GLM-5.1 | M2.7 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7 | 66.7 | 63.5 | 57.0 |
| SWE-Bench Pro | 58.6 | 58.6 | 58.4 | 56.2 |
| GPQA Diamond | 93.6 | 87.6 | 86.2 | 87.0 |
| HLE 有工具 | 52.2 | 51.8 | 52.3 | — |
| MCP Atlas | 75.3 | — | 71.8 | 48.8 |
| AA 综合智能指数 | 60 | — | 51.4 | 49.6 |
Kimi K2.6 在 SWE-Bench Pro 上和 GPT-5.5 打成平手(都是 58.6);GLM-5.1 的 HLE 有工具 52.3 甚至微微领先 GPT-5.5 的 52.2。这是开源阵营第一次在单项上贴脸顶级闭源。
(数据来源:OpenAI GPT-5.5 System Card、Anthropic Opus 4.7 文档、Artificial Analysis Intelligence Index 2026-04、Unsloth GLM-5.1 文档、MarkTechPost M2.7 开源报告、月之暗面 Kimi K2.6 官方博客)
三张表合起来帮你挑三条线。
第一条,GPT-5.5 的强项非常集中——长任务编程、电脑使用、前沿数学。 Terminal-Bench 2.0 比 Claude Opus 4.7 多出整整 13.3 个百分点,这是这一版最刺眼的赢面。FrontierMath Tier 4 上 GPT-5.5 把 Gemini 3.1 Pro 甩了 18.7 个百分点。ARC-AGI-2 领先 Opus 4.7 9.2 分。这三条合起来讲了一件事:GPT-5.5 把自己更紧地钉在了”开发者 Agent + 高难度推理”这个位置上。
第二条,Claude Opus 4.7 没有被盖过去。 SWE-Bench Pro 上它守着 64.3% 对 58.6%,MCP Atlas 79.1% 对 75.3%,HLE 有工具 54.7% 对 52.2%。简单说,“真实 GitHub 项目修复 + 工具链重度使用 + 综合考试”这三条线,Opus 4.7 还是第一。这也是为什么 Cursor、Windsurf 这些编程工具里,Claude 的用户没有因为 GPT-5.5 发布就集体切过去。
第三条,Gemini 3.1 Pro 是”学术 + 信息检索”的守门员。 GPQA Diamond 94.3 第一,ARC-AGI-1 98 第一,BrowseComp 85.9 第一。它不在 Terminal-Bench 2.0 上追赶,也不在 FrontierMath 上硬拼,但只要你问它”帮我研究一个东西”,它依然是最快、最准的那个。126 tok/s 的吐字速度全场最快,这点没有对手。
第四条,国产三家在单项上贴得很紧。 上面那张国产对照表已经告诉你结论——Kimi K2.6 追平 SWE-Bench Pro、GLM-5.1 在 HLE 上反超、M2.7 以最低价格做到榜上第二梯队。这一周的真正故事不是”GPT-5.5 赢了所有人”,是”每家都守住了自己的那一格”。
开发者与普通人的两种感受
跑分是官方实验室跑的,benchmark 和生活是两回事。我把这两天一线用户的真实反馈整理在这里——全部是公开发言,我逐条标了出处。
Jake Handy(Substack “Model Drop” 作者) 拿到了发布前 alpha 权限,他的原话是:
“GPT-5.5 takes OpenAI back to the clear number one in AI. 他们的综合智能指数第一次单独领先 3 分,打破了和 Anthropic、Google 三方并列的格局。但在很多个具体 benchmark 上,GPT-5.4 Pro 依然跑赢默认的 GPT-5.5——所以这不是一次 across-the-board 的压制,而是一次权重重分配。”
Michael Truell(Cursor CEO) 在发布日的推荐词写得很克制:
“The biggest thing we saw is that it stays on task for significantly longer without stopping early. 对 Codex 和 Cursor 用户来说,这是实打实的升级。但如果你只在 IDE 里做短任务,感知会没那么强。”
CodeRabbit(代码审查 Agent 平台) 在发布日跑了自己的评测基准,他们的结论是——GPT-5.5 在代码审查上的 expected-issue-found rate 从 55% 涨到了 65%,precision 从 11.6% 涨到 13.2%,发出的 comment 数量从 558 涨到 722。响应变快、变短、更偏向”做小修改不做大重写”。
孟健(Hermes 作者,国产模型一线使用者) 在腾讯云开发者社区发了他把 Kimi K2.6 接入 23 个 Agent 跑了一整天的实测报告:
“K2.6 目前是我用过的国产编程模型里最强的,思考和执行都比 GLM 5.1 更稳定、质量更高。但推理速度慢,单次请求的 first token 延迟比 GLM 5.1 慢一个量级。额度消耗也比预想快。”
Hacker News 上的社区反馈 集中在一条——GPT-5.5 和 GPT-5.4 的 tokens-per-second 基本一样,但同样的智能指数用的 token 更少。Reddit 一个高赞回复说得很直白:“GPT 5.4 in Codex is good enough now. Try it.”——意思是,GPT-5.4 在 Codex 里已经足够好用,GPT-5.5 的升级是锦上添花,不是必须。
把这几条合起来你会发现一件事——GPT-5.5 的升级更多是”开发者向”的。
长任务不早停、Codex 里省 token、数学和抽象推理的跳变、电脑使用追平 Anthropic——这些都是开发者和 Agent 使用者会在第一天感知到的。但如果你是一个普通的 ChatGPT Plus 用户,日常用法是问答、翻译、写稿、查资料——GPT-5.5 在你手里的体感差距,没有跑分那么大。
这不是 GPT-5.5 不行,是它这一版的用力方向没在你那一侧。
普通人到底该怎么选
讲了这么多参数和跑分,回到你最关心的问题——你今天晚上、明天、这一周,要不要动作?
我按”你是什么人”把它拆成三种——
第一种,你只是用 ChatGPT 聊天、写文案、查资料、做翻译。
不用升级 Pro。GPT-5.5 Thinking 已经在 Plus 档($20/月)里可用,日常对话你用不出 Pro 档的差异。Pro 档每月 $200,差的那 $180 你可以用来同时订 Claude Max 或 Gemini Advanced——任何一家的第二档订阅都比 ChatGPT Pro 性价比高。
如果你本来就没订,可以先不动。GPT-5.5 的 API 还没开放,等这一两周社区的第一批深度测评出来,再决定要不要掏钱也不迟。
第二种,你用 AI 写代码,或者在跑 Agent。
Codex 默认切 GPT-5.5 是成立的,长任务体感比 5.4 明显好一档。Cursor、Windsurf 等第三方工具会在 API 开放后第一时间接上。
但 Claude Opus 4.7 不要轻易卸载——SWE-Bench Pro 和 MCP Atlas 这两条线它还守着,在”修真实 GitHub issue + 多步工具链”这种场景下,Opus 4.7 的一次性通过率依然更稳。
更务实的做法是——两家都留,按任务类型切换。长任务 / 数学 / 电脑使用 → GPT-5.5;真实项目修复 / 重度工具链 / 长文写作 → Claude Opus 4.7;快速查资料 / 长文档阅读 → Gemini 3.1 Pro。
第三种,你是做中文内容的——营销、写作、知识付费、效率流水线。
国产三家的性价比已经到了”没理由不用”的程度。
GLM-5.1 的中文质感、Kimi K2.6 的代码能力、MiniMax M2.7 的低价 API,这三家拼起来能覆盖 90% 的日常中文场景,而且总成本只有订一家 ChatGPT Pro 的几分之一。
很多人不用是因为”国产 = 差”的印象还没扭过来。但 2026 年 4 月这一周发生的事情,已经不是”国产追赶国外”了——开源阵营的前十个模型里,中国占了六席。Kimi K2.6 在 SWE-Bench Pro 上直接和 GPT-5.5 打平,GLM-5.1 在中文任务里比任何国外模型都顺。这个格局过去一年只会继续加深。
讲到这里我想收个尾。
OpenAI 发布 GPT-5.5 的那天,首席科学家 Jakub Pachocki 在发布会上说了一句话——“过去两年的模型进展令人惊讶地缓慢”。
我第一眼看到这句话是笑了一下。过去两年 AI 进展还叫缓慢,那以前叫什么。但想一想他说的也不是没道理。从 GPT-4 到 GPT-5.4,模型确实一直在”变聪明”,但那种聪明是”知道得更多、算得更快、考得更高”。跑分的表格一年比一年好看,但每一版升级对普通人的体感差距,却一年比一年小。
这一周六个旗舰同时交卷,反而让我看清楚一件事——
AI 旗舰的竞争,已经从”谁更聪明”,变成了”谁更适合什么人”。
开发者去用 GPT-5.5,写代码去用 Claude Opus 4.7,查资料去用 Gemini 3.1 Pro,做中文内容去用 GLM-5.1 或 Kimi K2.6,跑大批量生成去用 MiniMax M2.7。
一个模型打天下的时代,大概就在这一周里结束了。
你呢——这一周你是打算动,还是打算先等等?
- OpenAI 官方博客 Introducing GPT-5.5(2026-04-23)
- Anthropic 官方 Claude Opus 4.7 发布文档(2026-04-17)
- 主流科技媒体:TechCrunch、The Verge、CNBC、New York Times、VentureBeat、The Decoder、CNET(2026-04-23)
- 深度拆解:Jake Handy《Model Drop: GPT 5.5》(handyai.substack.com)、CodeRabbit GPT-5.5 Benchmark Report、Hacker News 社区反馈
- 对比数据:Artificial Analysis Intelligence Index(2026-04)、Unsloth GLM-5.1 文档、MarkTechPost MiniMax M2.7 开源报告、月之暗面 Kimi K2.6 官方博客
- 中文一线反馈:孟健 Hermes 接入 Kimi K2.6 实测(腾讯云开发者社区)、新智元、36氪