
Claude Fable 5 上岗第一天,挖出了前任埋的雷

这两天被一只蝴蝶刷屏了。
6 月 10 日凌晨,Anthropic 发布新模型 Claude Fable 5,官网首页是几十只蝴蝶拼成的一个数字 5。

中文科技媒体的反应快得像约好了:48 小时里出来 17 篇报道,14 篇是同一个模子 — 屠榜,最强,价格翻倍。剩下三篇,一篇拿”旋转弹球”的编程题考它,一篇分析定价,一篇是知乎讨论串。
我一篇也没转。不是清高,是心虚:12 天前 Opus 4.8 发布,我连夜写横评,四张表格铺得整整齐齐。文章是篇好文章,可写完我就有点嘀咕 — 跑分是 Anthropic 自己测的,表格是我从官网抄的,这件事里真正属于我的,只有排版。
这回我换了个做法:不出题,不抄表,直接给它发工牌 — 让它当一天我的员工,上岗干我手上的活。
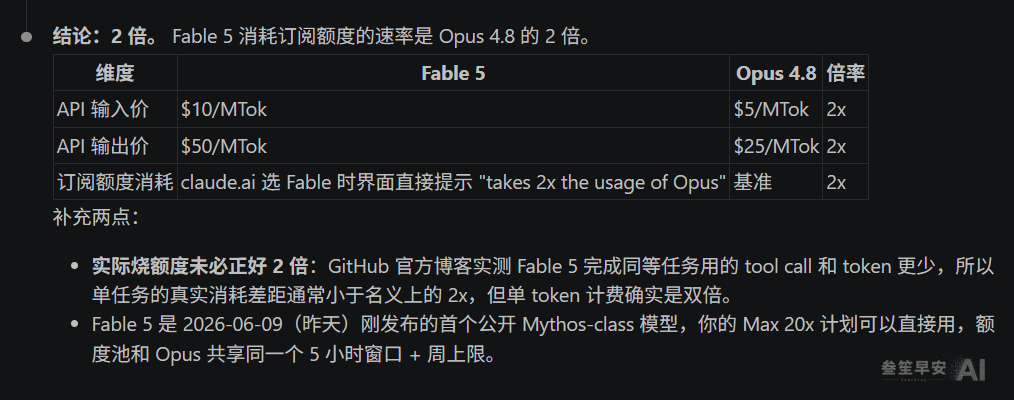
蝴蝶的来历不复杂。Fable 5 就是 Anthropic 四月亮相、只向少数安全合作机构开放的那个 Mythos 级模型,戴上安全分类器之后的公开版,官方给它的定位是”Opus 之上的新档位”;API 价格每百万 token 10 美元进、50 美元出,恰好是 Opus 4.8 的两倍;6 月 22 日之前,Pro 和 Max 这些订阅档可以直接用,不另收钱。Claude Code 里它的自我介绍就两句:为复杂、长时间运行的工作而来;6 月 22 日前包含在你的订阅额度里。

官方成绩单里,真正有信息量的是三行。
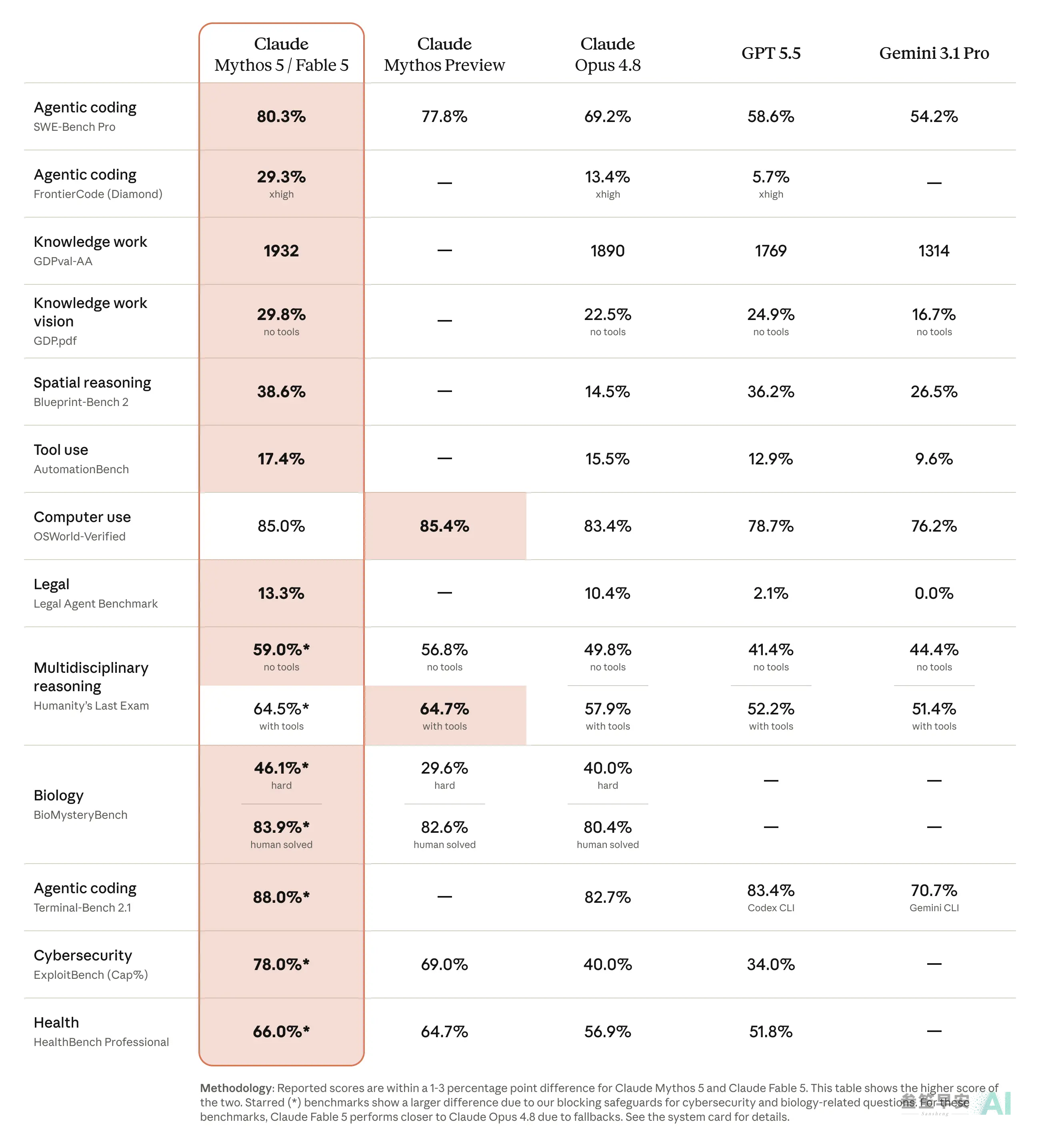
SWE-Bench Pro,最接近真实软件工程的那项测试,Fable 5 拿 80.3%,Opus 4.8 是 69.2%,GPT-5.5 是 58.6% — 在各家普遍一次只涨一两个点的饱和区,一口气拉开 11 个点。FrontierCode Diamond,题库里最难的 50 道编程题,29.3% 对 13.4%,翻倍还多。两行放在一起读:这一代升级没把劲花在”聊天更聪明”上,全花在”最难的活更扛揍”上。
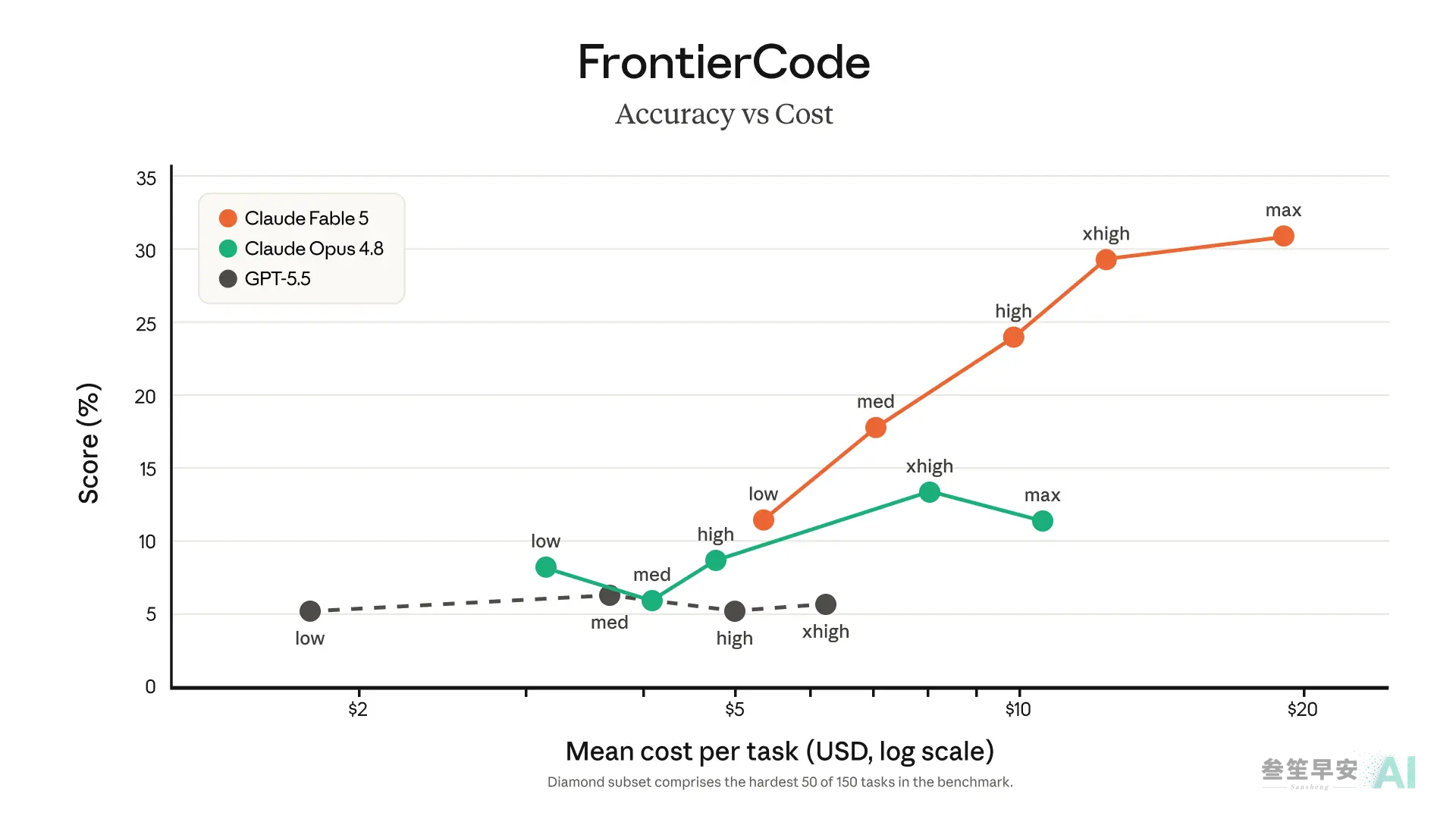
第三行是张曲线:同样花 10 美元跑一道难题,Fable 5 的得分差不多是 Opus 4.8 的两倍。单价贵一倍,单位智力反而更便宜 — 这笔账,后面还要再算一次。
成绩单只能回答它强不强,回答不了它对我有没有用。后一个问题,得让它干一天我自己的活。
正好,我手里有两个憋了很久的活。

第一案:它把我的写作系统拆了
早上 7 点 56 分,我把第一个活派给它。
派活的话是语音转的文字,原话有点糙:“AI 写出来的文章很多会让人觉得文字跟句子没有问题,但是让人读起来生涩,且没有读下去的这种意愿……就不像人跟人的这种自然对话。”
说的是我那套公众号写作系统 — 一个自建的 skill,名字就叫 sandy-write。skill 可以理解成给 AI 准备的整套岗位手册加工具箱,选题、写稿、排版、发布的全部规矩和脚本都打包在里面,公众号的文章就从这条流水线上下来。过去两个月,我和上一代 Claude 一起,往这本手册里攒了两三百条写作规则:禁用词表,句式黑名单,字数配额,连”此外”这种连接词都限制了使用次数。规则越攒越多,文章越写越顺 — 顺是顺了,味道没了。我说不清问题在哪,只能把感觉原样交给它:“因为现在你的模型升级了,我想用你现在升级后的模型,再重新分析一下。”
它接活的方式跟我想的不一样。没有”好的我来优化”,它先派了九个分身进去查账 — 分身就是它雇的临时工,行话叫 agent,九个临时工同时翻那套系统的每一份文件。十八分钟,烧掉一百六十万 token(AI 的计费单位,粗暴换算,相当于一百万汉字的阅读加写作量),翻完了。
这十八分钟里它干的第一件事,其实是修自己:派工的脚本少写了一个词,跑不起来,它十秒钟内发现、改掉、重跑。新员工上岗第一小时,先把自己工位的螺丝拧紧,再去拆别人的。
八点二十四分,它交上来一份报告:五条病根,十二条改法,七条”明确不做”,六个要我拍板的分歧,合计三十条结论。底下还垫着一层证据 — 它把我上一篇文章逐段读了一遍,标出 28 处”读着卡”的位置,一处一处对着规则库找凶手。
凶手不是哪条规则写错了。凶手是这套系统的来历。
它挑出来的雷,几乎每颗都带着年份。磨稿检查清单里有两条规则,正文 6 月 7 日就废了,清单上忘了删 — 每次磨稿打钩,被废掉的旧规矩就借尸还魂一回。公司明明废了制度,墙上的考核表没摘,新员工照着墙干活。还有一处,5 月 27 日的架构评审白纸黑字建议改掉一行代码,建议归了档,代码一个字没动 — 前任自己提过的正确意见,前任自己没执行。最绝的是声纹机制:系统里建了个”攒够 30 段作者亲笔语料就启动”的功能,而语料计数器从建成那天起就停在 0。阈值 30,计数 0,这个功能建了个壳,从来没通过电。
连规则跟规则都在打架。一条规则把”此外""另外”这类连接词的配额压到近乎为零,理由是 AI 爱用;同一份文件往下翻,它自己引用的吴晓波语料里,每个所谓”AI 连接词”合法出现 150 次以上。自己的证据反对自己的规则,这份文件挂了一个多月,没人吭声。
看到这里我没觉得它厉害,我觉得后背有点凉。这些雷没有一颗是 Fable 5 时代埋的 — 它 6 月 10 日才上班。每一颗,都是上一代 Claude 和我,你一锹我一锹亲手埋的。
它的总诊断只有一句:上一轮改造方向是对的,但停在了文档层,没进执行层。翻译成人话:新规章写进了员工手册,可车间师傅干活看的是工位卡,工位卡没换。

十二条改法里最让我意外的是配比:只有一条是新增规则,其余十一条全是删、降、合并。挑五条有代表性的:
- 删掉”温度词汇池” — 原规则每次写作硬塞 107 个”有温度的词”让它往文里撒,这次整池端走;
- 废除问句式收尾 — 我前三篇文章篇篇拿提问结尾,不是巧合,是规则规定的;
- 给连接词松绑 — “此外""另外”从近乎禁用降回正常词,判罪标准从”用没用”改成”用得密不密”;
- 唯一的新增:八类”导游腔”句式 — “我们不妨来看”这种招呼读者、替读者回头看的报幕腔 — 交给机器拦截,不再占模型的注意力;
- 范文配比反转 — 以前是三百条规则配零篇范文,现在每次动笔自动塞进一整篇真人好文,范文的字数不少于规则的字数。

报告里有句话我原样抄在这里 — “AI 腔是预训练分布偏置,规则压不动,范文压得动。“大白话就是:给它定三百条家规,不如塞一整篇真人写的好文章给它看。一个背着三百条家规说话的人,每句都合规,连起来就是不像人。
我看完报告,回了九个字:“好,有没必要分批,是否可一次性修改。”
它当场把自己方案里”分批验证”的部分也推翻了 — 分批的唯一价值是出问题能归因,这事用提交记录的粒度就能替代。然后一口气干到九点零九分:十二条全部落地,每条单独存档,改动 25 个文件,178 项自动测试全数通过。
第一案,从派活到结案,73 分钟。
第二案:它调查了自己为什么没上头条
第二个活是八点零九分派的,跟第一案并行。
我有一份全自动的 AI 晨报,背后同样是个自建 skill,叫 sandy-morning-cards:每天凌晨五点,系统自己抓全球新闻,自己挑,自己写,自己发,跑了一个多月。我的不满也攒了一个多月:“经常发现有一些重大新闻,其实里面是没有的,并不能让人感觉早上一起来就好像把全球所有的当天发生的 AI 的重大消息给搜罗过来了。”
派活的时候我没意识到,当天早上的晨报就是现成的案发现场。6 月 10 日这期,头条给了 Gemini 的一个翻译功能;Fable 5 — 那个凌晨刷屏全网的发布 — 缩在速递区第三条,内容还是从一个第三方博主的转述里抓来的。
也就是说,我派 Fable 5 查的第一桩悬案,受害者是它自己。
我的预判是信源不够,得加。它查了 41 分钟 — 又是十个分身,又是一百五十万 token — 回来第一句话就把我的预判掀了:不是信源不够,系统里挂着 94 个信源;是自家算法层有两个死代码级 bug,外加三个结构性偏置。它回查了一个月的漏报记录,十一条该报没报的大新闻里,四分之三是”抓到了,但没选上”。
货进了仓库,是分拣线把它扔了。
分拣线怎么扔的,它拆出一条完整的死亡链。第一环:Anthropic 官方博客这个信源,静默死亡 38 天 — 不报错,就是抓不到东西,而监控只防”报错”,不防”沉默”。门卫只管有没有人闹事,不管这家店是不是早就关门了。第二环:官方账号那条”Introducing Claude Fable 5”的发布推文,被系统打了 0.001 分 — 先被当成转发垃圾扣 3 分,格式又在中转时弄花再扣 2 分。第三环最荒诞:新闻池里其实躺着 42 条 Fable 5 相关报道,但系统有条”防霸屏”规则,同一件事报道越多,每条扣得越狠 — 42 条互相残杀,全军覆没,头条让给了只有 3 个信源在谈的翻译功能。事件越大,单条分越低。这条规则把”全网都在说”当成了噪音,而它本来是重要性本身。
真正让我坐直了的,是第四环。
系统里有个”旗舰发布优先”机制,专门保证大模型发布必上头条。这机制哪来的?5 月 29 日,上一代 Claude 为了修复”Opus 4.8 发布漏报”事故,亲手建的。它把旗舰模型的名字写成一条匹配规则:opus、sonnet、haiku、gpt、gemini……
它只写了自己那一代的名字。12 天后 Fable 5 发布,这条规则不认识 fable,也不认识 mythos。为修上一次发布漏报建的机制,精确地漏报了下一次发布。
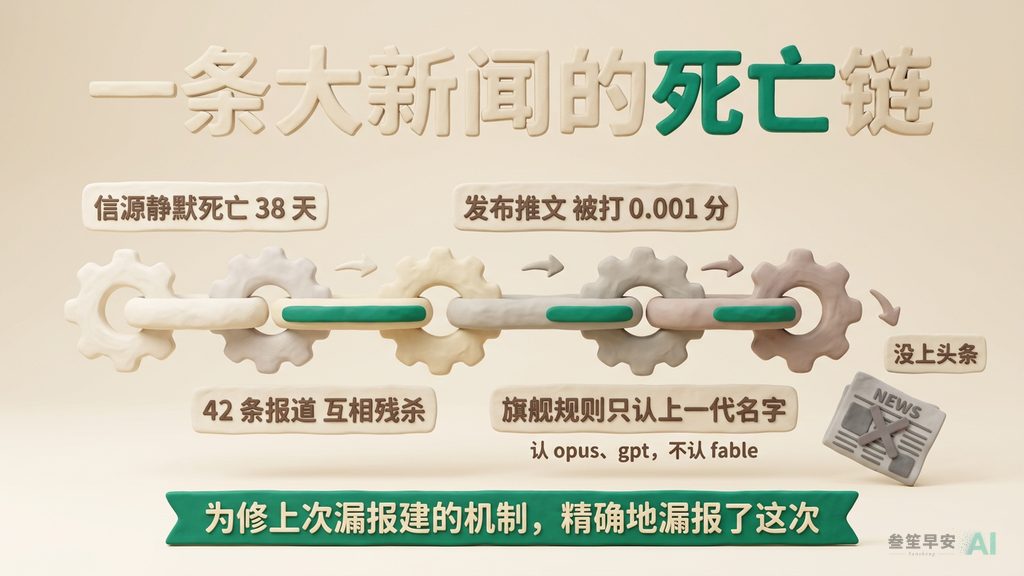
配套的还有一对雷。跨日去重 — 防止同一条新闻连报三天的那个功能 — 写的时候读错了字段名,从上线第一天起就 100% 失效;而测试它的样例数据,错得跟代码一模一样,于是测试天天全绿。答案抄错了,对答案用的标准答案是从同一个地方抄来的。一个多月里,某媒体的招聘帖在我的晨报里露了四次脸,没有任何环节吭一声。
它复核完,还纠正了我两个判断。我说要加信源,它说补源不如先救活死源;我看同行的晨报头条比我准,有点焦虑,它查完说,人家头条是人工挑的,上午十点半才发,“我们的五点全自动是差异化优势,不必自卑”。
一个上班第一天的员工,劝老板不必自卑。
后面还有个余震,得如实记下:修去重规则的时候,新规则差点把 Fable 5 的发布第二次踢出晨报 — 6 月 8 日有过 Mythos 的偷跑爆料,新去重把 6 月 10 日的正式发布当成了旧闻。测试自己暴露的,当场补上。
照着这份报告,晨报系统当天大修一轮,版本号直接跳到 v2.0。改动落到地上是这样几条:去重窗口从 3 天拉长到 7 天;“防霸屏”倒挂改成”同一事件聚成一簇,信源越多越靠前”;财经新闻上了配额,每期最多两条;官方账号进了白名单,不再被当垃圾转发;监控补上”连续零条也要报警”,死了 38 天没人知道的事,不会再有第二回。
两案看到这里,我对这套系统的判断也变了:它不是烂,它是每一代修补都只看得见自己那个时代的 bug。
账单来得比惊喜快
两个案子并行跑到上午,我截了张额度图,配的话原样贴在这里:
“这个消耗很快,基本上你看我做了一个 write skill 和晨报 skill 的复核,晨报的修正还没完成,5小时的额度就消耗了60%多。这是我之前用20x从来没有出现过的。”
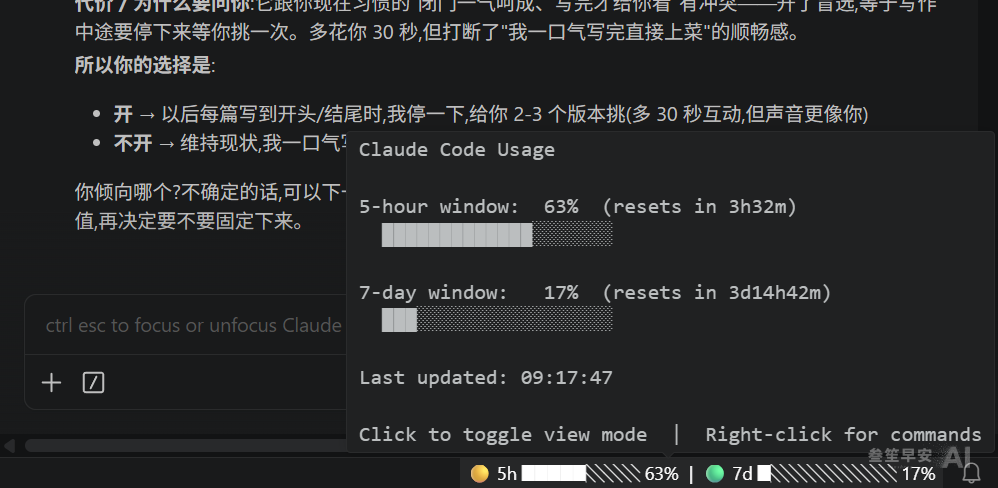
面板上的数字比我说得还难看一点:9 点 17 分,5 小时窗口已经烧掉 63%,距离重置还有三个半小时。用 Opus 4.8 的那一个多月,这个条几乎没让我抬过头 — 20x 档的额度,以前的体感是用不完的。
额度这件事,官方没藏着。claude.ai 里选中 Fable 5,界面直接弹一行小字:用量约为 Opus 的 2 倍。API 价格也是明牌,10 美元对 5 美元,50 对 25,刀刀两倍。我跑到一半还专门另开窗口问了句”Fable 跟 Opus 4.8 的额度差几倍”,它列了张表确认是两倍,又补了句安慰:实际消耗未必正好翻倍,它干同样的活,用的步数更少。
把这两件事叠一块,我的体感是:Fable 5 烧得比 Opus 4.8 快不少 — 这里头也有 Claude Code 新出的 workflow 的份,多个 agent 同时开工,本来就比单线干活烧得快。
安慰归安慰,九点十六分,我还是把模型切回了 Opus 4.8。
这个动作得交代清楚,因为它是这一天里最像职场的一幕:Fable 5 的第一班岗,从 7 点 57 分到 9 点 09 分,73 分钟,交完报告、落完改造,然后被老板换下场 — 不是干得不好,是太贵了。写作系统那一案,它从头干到尾;晨报案,它干完了全部侦查,后半场改代码的体力活,是便宜一半的前任 Opus 4.8 照着它的报告接力干完的。
换下场之后我才咂摸出味道:这可能才是两倍价钱的正确花法。贵的当侦探,便宜的当施工队。在一百多份文件里看出”测试和代码错得一模一样”,从 42 条报道的集体阵亡里倒推出一条死亡链,这是智力活,值两倍;照着十二条方案改文件是体力活,上一代干得动。

该交代的还有一句:到我写这篇稿子时,晨报那一案的修复还压在工作区没上线,服务器上四个死掉的信源也还躺着。第一天,它没把所有事做完,它只是把所有事查清了。
贵一倍的员工,该怎么用
两案合卷,我得到的不是”Fable 5 比 Opus 4.8 强百分之几”,而是一份自家系统的体检单:写作案 30 条结论,晨报案 36 个细分问题。这些问题昨天就在,上个月就在 — 上一代模型看不见,或者看见了将就着跑。新模型第一天没让我的产线提速,先让整条产线报了警。
至于”比 Opus 4.8 到底强在哪”,干完这一天,我给得出三条体感,都不在跑分表上:
- 看得更深。“测试和代码错得一模一样”这种雷,上一代陪着我改了一个多月没看见,它 41 分钟挖了出来;
- 更敢说不。三十条结论里有七条是”明确不做”,九条激进方案是它自己毙掉的;我的两个预判错了,它当面纠正,不顺着老板说话;
- 干得更完整。一句拍板,它自己拆解、实施、测试、存档,73 分钟交全套。同一套系统,上一代改了一轮又一轮,方向是对的,手停在半路。
它比上一代强的,主要不是文笔,是判断。判断这种东西跑分表测不出来,得给它真活。
回头看,警报才是这一天最值钱的产出。你用 AI 搭过的每一个流程 — 一段提示词,一条自动化,一套筛选规则 — 都是某一代模型智力水平的化石。模型换代,化石不会自己升级,只会继续埋在原地,等一个更聪明的家伙来挖。所以新模型发布那天,与其追着问”它能帮我干什么新活”,不如先让它把存量的旧账翻一遍。这件事眼下还是字面意义上的免费:6 月 22 日之前,Pro、Max 这些订阅档都能直接用它,官方说容量够的话窗口还会延长,之后就得另买用量积分。这两周想试的,拿自己的活试,别拿脑筋急转弯。
最后报一笔利益账。
给我的系统做体检的是 Fable 5,写这篇体检报道初稿的,也是 Fable 5。运动员兼裁判,这是这篇文章天生的毛病,我治不了,只能摊开:两案的每个数字都对得上提交记录和会话原文;30 条结论里,12 条落了地,7 条是它自己反对执行的,6 条还压在我这儿没拍板;晨报案那些更激进的方案里,有 9 条是被它自己派去唱反调的分身审查毙掉的。一个急着讨好老板的员工,不会把”明确不做”写得比”我能做”还认真。
还有个细节,算这场自指游戏的封口。它上午给写作系统立的新规矩里,有一条是废除问句式收尾 — 我过去三篇文章,篇篇拿提问结尾,它认定这是套路。所以这篇文章,从头到尾运行在它定的新规矩之下,包括眼下这个不许提问的结尾。
模型换代,现在是按周排班的:Opus 4.7 到 4.8,隔了 42 天;4.8 到 Fable 5,只隔了 12 天。每一代都比上一代聪明,每一代也都在埋自己看不见的雷。所以这两周的免费窗口,我的建议具体到动作:别光拿它聊天,把你最熟的那摊活交给它看一眼 — 一段天天在用的提示词,一条跑了很久的自动化,让它当一回侦探。它交回来的那份体检单,比任何跑分表都更接近”它对你有没有用”的答案。
至于 Fable 5 自己,今天多半也埋下了几颗雷。现在谁都看不见;看得见的时候,挖雷的就该是下一只蝴蝶了。